福利 => 每天都推送
前言
本人呕心沥血所写,经过好一段时间反复锤炼和整理修改。感谢所参考的博友们!同时,欢迎前来查阅赏脸的博友们收藏和转载,附上本人的链接。http://www.cnblogs.com/zlslch/p/5847528.html
关于几个疑问和几处心得!
a.用NAT,还是桥接,还是only-host模式?
答: hostonly、桥接和NAT
b.用static的ip,还是dhcp的?
答:static
c.别认为快照和克隆不重要,小技巧,比别人灵活用,会很节省时间和大大减少错误。
d.重用起来脚本语言的编程,如paython或shell编程。
对于用scp -r命令或deploy.conf(配置文件),deploy.sh(实现文件复制的shell脚本文件),runRemoteCdm.sh(在远程节点上执行命令的shell脚本文件)。
e.重要Vmare Tools增强工具,或者,rz上传、sz下载。
f.大多数人常用

Xmanager Enterprise *安装步骤
用到的所需:
1、VMware-workstation-full-11.1.2.61471.1437365244.exe
2、CentOS-6.5-x86_64-bin-DVD1.iso
3、jdk-8u60-linux-x64.tar.gz
4、hadoop-2.6.0.tar.gz
5、scala-2.10.4.tgz
6、spark-1.6.1-bin-hadoop2.6.tgz
机器规划:
192.168.80.100---------------- SparkSignleNode
目录规划:
1、下载目录
/usr/loca/ ---------------- 存放所有安装软件
2、新建目录
3、安装目录
jdk-8u60-linux-x64.tar.gz -------------------------------------------------- /usr/local/jdk/jdk1.8.0_60
hadoop-2.6.0.tar.gz ---------------------------------------------------------- /usr/local/hadoop/hadoop-2.6.0
scala-2.10.4.tgz --------------------------------------------------------------- /usr/local/scala/scala-2.10.4
spark-1.6.1-bin-hadoop2.6.tgz ---------------------------------------------- /usr/local/spark/spark-1.6.1-bin-hadoop2.6
4、快照步骤
快照一:
刚安装完毕,且能连上网
快照二:
root用户的开启、vim编辑器的安装、ssh的安装、静态IP的设置、/etc/hostname和/etc/hosts和永久关闭防火墙
SSH安装完之后的免密码配置,放在后面
静态IP是192.168.80.100
/etc/hostname是SparkSingleNode
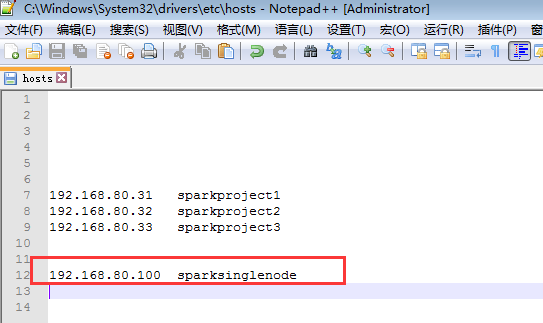
/etc/hosts是
192.168.80.100 SparkSingleNode
快照三:
安装jdk、安装scala、配置SSH免密码登录、安装python及ipython (这里,选择跳过也可以,ubuntu系统自带安装了python)
新建spark用户,(即用spark用户,去安装jdk、scala、配置SSH免密码、安装hadoop、安装spark...)
快照四:
安装hadoop(没格式化)、安装lrzsz、将自己写好的替换掉默认的配置文件、建立好目录
快照五:
安装hadoop(格式化)成功、进程启动正常
快照六:
spark的安装和配置工作完成
快照七:
启动hadoop、spark集群成功、查看50070、8088、8080、4040页面
第一步:
安装VMware-workstation虚拟机,我这里是VMware-workstation11版本。
详细见 ->
VMware workstation 11 的下载
VMWare Workstation 11的安装
VMware Workstation 11安装之后的一些配置
第二步:
安装ubuntukylin-14.04-desktop系统 (最好安装英文系统)
详细见 ->
CentOS 6.5的安装详解
CentOS 6.5的安装详解
CentOS 6.5安装之后的网络配置
CentOS 6.5静态IP的设置(NAT和桥接都适用)
CentOS 命令行界面与图形界面切换
网卡eth0、eth1...ethn谜团
Centos 6.5下的OPENJDK卸载和SUN的JDK安装、环境变量配置
第三步:VMware Tools增强工具安装
详细见 ->
VMware里Ubuntukylin-14.04-desktop的VMware Tools安装图文详解
第四步:准备小修改(学会用快照和克隆,根据自身要求情况,合理位置快照)
详细见 ->
CentOS常用命令、快照、克隆大揭秘
E:Package 'Vim' has no installation candidate问题解决
新建用户组、用户、用户密码、删除用户组、用户(适合CentOS、Ubuntu)
1、root用户的开启(Ubuntu系统,安装之后默认是没有root用户)
2、vim编辑器的安装
3、ssh的安装(SSH安装完之后的免密码配置,放在后面)
4、静态IP的设置
CentOS 6.5安装之后的网络配置
5、/etc/hostname和/etc/hosts
root@sparksinglenode:~# cat /etc/hostname
sparksinglenode
root@sparksinglenode:~# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.80.100 sparksinglenode
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
6、永久关闭防火墙
一般,在搭建hadoop/spark集群时,最好是永久关闭防火墙,因为,防火墙会保护其进程间通信。
root@SparkSingleNode:~# sudo ufw status
Status: inactive
root@SparkSingleNode:~#
新建用户组、用户、用户密码、删除用户组、用户(适合CentOS、Ubuntu)
这个知识点,模糊了好久。!!!
生产中,习惯如下:
useradd,默认会将自身新建用户,添加到同名的用户组中。如,useradd zhouls,执行此命令后,默认就添加到同名的zhouls用户组中。
但是,在生产中,一般都不这么干。通常是,useradd -m -g 。否则,出现到时,用户建立出来了,但出现家目录没有哦。慎重!!!(重要的话,说三次)
####################CentOS系统里##########################
CentOS系统里,root用户下执行
第一步:groupadd 新建用户组
groupadd hadoop 这是创建hadoop用户组
第二步:useradd -m -g 已创建用户组 新建用户
useradd -m -g hadoop hadoop 这是新建hadoop用户和家目录也创建,并增加到hadoop组中
第三步:passwd 已创建用户
passwd hadoop hadoop用户密码
Changing password for user hadoop
New password :
Retype new password:
###################################
安装前的思路梳理:
***********************************************************************************
* *
* 编程语言 -> hadoop 集群 -> spark 集群 *
* 1、安装jdk *
* 2、安装scala *
* 3、配置SSH免密码登录(SparkSingleNode自身)
* 4、安装python及ipython (这里,选择跳过也可以,ubuntu系统自带安装了python)
* 5、安装hadoop *
* 6、安装spark *
* 7、启动集群 *
* 8、查看页面 *
* 9、成功(记得快照) *
*******************************************************
一、安装jdk
记得,这里先卸载CentOS6.5自带的openjdk,具体怎么做,请见上述的博客。我已经写了很清楚。
jdk-8u60-linux-x64.tar.gz -------------------------------------------------- /usr/local/jdk/jdk1.8.0_60
1、jdk-8u60-linux-x64.tar.gz的下载
下载,http://download.csdn.net/download/aqtata/9022063
2、jdk-8u60-linux-x64.tar.gz的上传
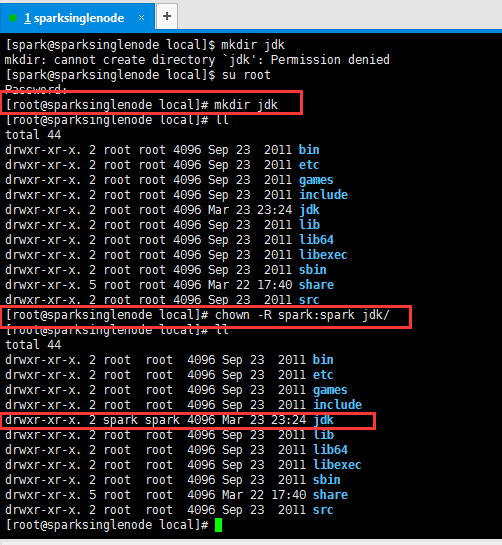
[root@sparksinglenode local]# mkdir jdk
[root@sparksinglenode local]# chown -R spark:spark jdk

[root@sparksinglenode jdk]# yum -y install lrzsz
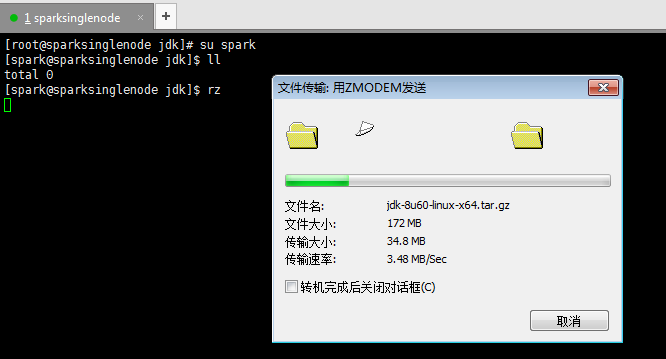
3、解压jdk文件

[spark@sparksinglenode jdk]$ tar -zxvf jdk-8u60-linux-x64.tar.gz
4、删除解压包,留下解压完成的文件目录,并修改权限(这是最重要的!)
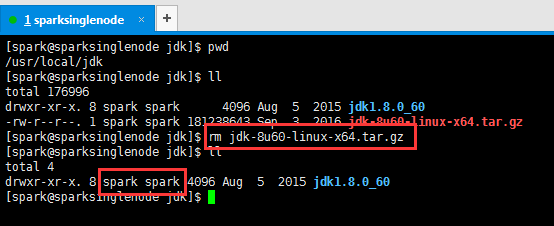
[spark@sparksinglenode jdk]$ rm jdk-8u60-linux-x64.tar.gz
5、修改环境变量
vim ~./bash_profile 或 vim /etc/profile
配置在这个文件~/.bash_profile,或者也可以,配置在那个全局的文件里,也可以哟。/etc/profile。
这里,我vim /etc/profile

[spark@sparksinglenode jdk]$ su root
Password:
[root@sparksinglenode jdk]# vim /etc/profile
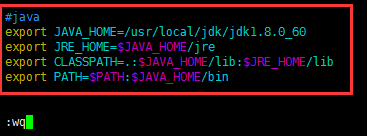
#java export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin
6、生效jdk环境变量
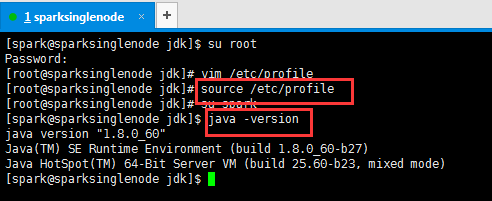
[root@sparksinglenode jdk]# source /etc/profile
[root@sparksinglenode jdk]# su spark
[spark@sparksinglenode jdk]$ java -version
二、安装scala
scala-2.10.5tgz --------------------------------------------------------------- /usr/local/scala/scala-2.10.5
1、scala的下载
http://www.scala-lang.org/files/archive/
或者
http://www.scala-lang.org/download/2.10.5.html

2、现在,新建/usr/loca/下的sacla目录
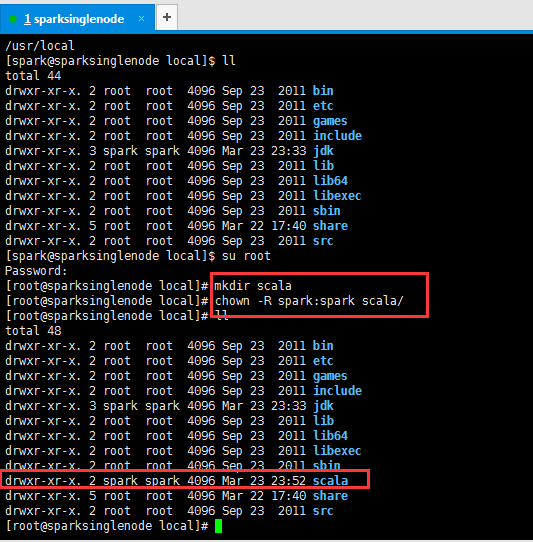
3、scala-2.10.5.tgz 的上传
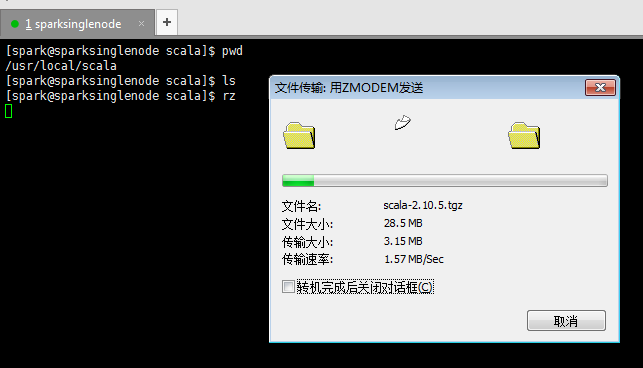
[spark@sparksinglenode scala]$ rz

4、解压scala文件

[spark@sparksinglenode scala]$ tar -zxvf scala-2.10.5.tgz
5、删除解压包,留下解压完成的文件目录,并修改权限(这是最重要的!!!)
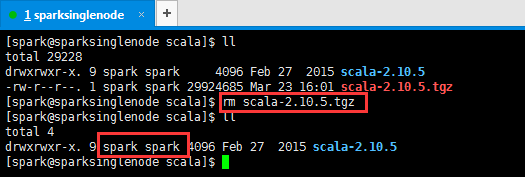
[spark@sparksinglenode scala]$ rm scala-2.10.5.tgz
6、修改环境变量
vim ~./bash_profile 或 vim /etc/profile
配置在这个文件~/.bash_profile,或者也可以,配置在那个全局的文件里,也可以哟。/etc/profile。
这里,我vim /etc/profile

[spark@sparksinglenode scala]$ su root
Password:
[root@sparksinglenode scala]# vim /etc/profile
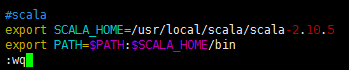
#scala export SCALA_HOME=/usr/local/scala/scala-2.10.5 export PATH=$PATH:$SCALA_HOME/bin
7、生效scala环境变量
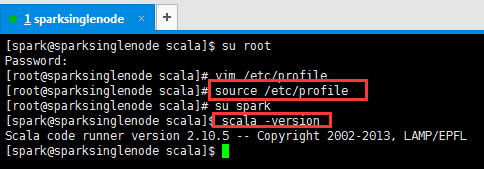
[root@sparksinglenode scala]# source /etc/profile
[root@sparksinglenode scala]# su spark
[spark@sparksinglenode scala]$ scala -version
三、配置免密码登录
1、配置SSH实现无密码验证配置,首先切换到刚创建的spark用户下。
因为,我后续,是先搭建hadoop集群,在其基础上,再搭建spark集群,目的,是在spark用户下操作进行的。
所以,在这里,要梳理下的是,root和zhouls,都是管理员权限。在生产环境里,一般是不会动用这两个管理员用户的。
由于spark需要无密码登录作为worker的节点,而由于部署单节点的时候,当前节点既是master又是worker,所以此时需要生成无密码登录的ssh。方法如下:
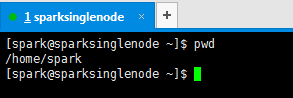
[spark@sparksinglenode ~]$ pwd
/home/spark
2 、创建.ssh目录,生成密钥
mkdir .ssh
ssh-keygen -t rsa 注意,ssh与keygen之间是没有空格的
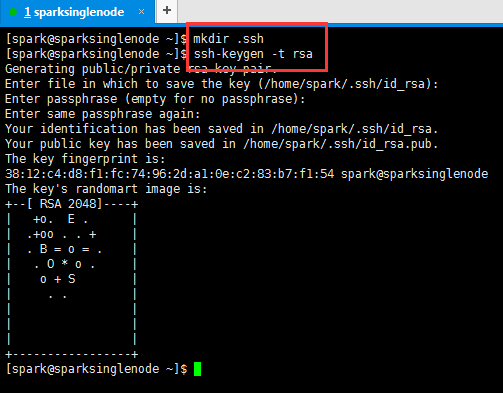
[spark@sparksinglenode ~]$ mkdir .ssh [spark@sparksinglenode ~]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/spark/.ssh/id_rsa): (回车) Enter passphrase (empty for no passphrase): (回车) Enter same passphrase again: (回车) Your identification has been saved in /home/spark/.ssh/id_rsa. Your public key has been saved in /home/spark/.ssh/id_rsa.pub. The key fingerprint is: 38:12:c4:d8:f1:fc:74:96:2d:a1:0e:c2:83:b7:f1:54 spark@sparksinglenode The key's randomart image is: +--[ RSA 2048]----+ | +o. E . | | .+oo . . + | | . B = o = . | | . O * o . | | o + S | | . . | | | | | | | +-----------------+ [spark@sparksinglenode ~]$
3 、切换到.ssh目录下,进行查看公钥和私钥
cd .ssh
ls
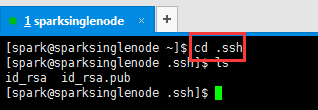
[spark@sparksinglenode ~]$ cd .ssh
[spark@sparksinglenode .ssh]$ ls
id_rsa id_rsa.pub
[spark@sparksinglenode .ssh]$
4、将公钥复制到日志文件里。查看是否复制成功
cp id_rsa.pub authorized_keys
ls

[spark@sparksinglenode .ssh]$ cp id_rsa.pub authorized_keys
5、查看日记文件具体内容

[spark@sparksinglenode .ssh]$ cat authorized_keys ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAtCbvAZr07dAiUG66PcyXFBZX+2wfyi9lv0Dv8X2EfVbXakDaRRGHGBQ/k3KTXMtmziijcuTtDJJoSuC7tZVp00l+jNVB5UPIBsAPTCidUXECLUUVNDFNmzzFWumAtiJd7yeQMCEZyUX7TQ00IaDG5hqzgneZRaek+sARPJnvvn+USKH1pJI3iPstbDhWVKqWg2UBmEkoAtZUmP4ZsiExwysRaFCyETVqPZ3qxMCe/yhhxaWtnl71lIHQJsYy15cUdxnaBWM/XJEEINRFplVAgR9wIkIBexYBGZpu8uLOT7oQiCgQ0CixgKAwEN7BaaTDMBue0ebwWsaByyzb964gyQ== spark@sparksinglenode
6、退回到/home/spark/,来赋予权限
cd ..
chmod 700 .ssh 将.ssh文件夹的权限赋予700
chmod 600 .ssh/* 将.ssh文件夹里面的文件(id_rsa、id_rsa.pub、authorized_keys)的权限赋予600

[spark@sparksinglenode ~]$ chmod 700 .ssh [spark@sparksinglenode ~]$ chmod 600 .ssh/*
7、测试ssh无密码访问
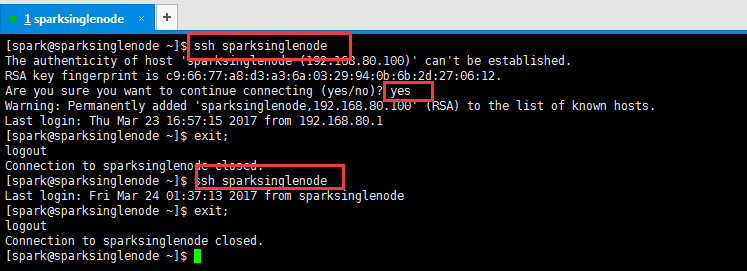
[spark@sparksinglenode ~]$ ssh sparksinglenode The authenticity of host 'sparksinglenode (192.168.80.100)' can't be established. RSA key fingerprint is c9:66:77:a8:d3:a3:6a:03:29:94:0b:6b:2d:27:06:12. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'sparksinglenode,192.168.80.100' (RSA) to the list of known hosts. Last login: Thu Mar 23 16:57:15 2017 from 192.168.80.1 [spark@sparksinglenode ~]$ exit; logout Connection to sparksinglenode closed. [spark@sparksinglenode ~]$ ssh sparksinglenode Last login: Fri Mar 24 01:37:13 2017 from sparksinglenode [spark@sparksinglenode ~]$ exit; logout Connection to sparksinglenode closed. [spark@sparksinglenode ~]$
四、安装hadoop
hadoop-2.6.0.tar.gz ---------------------------------------------------------- /usr/local/hadoop/hadoop-2.6.0
1、hadoop的下载
http://archive.apache.org/dist/hadoop/common/hadoop-2.6.0/

2、hadoop-2.6.0.tar.gz的上传
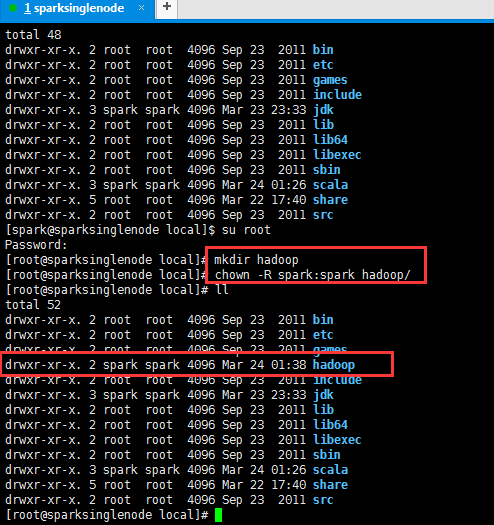
total 48 drwxr-xr-x. 2 root root 4096 Sep 23 2011 bin drwxr-xr-x. 2 root root 4096 Sep 23 2011 etc drwxr-xr-x. 2 root root 4096 Sep 23 2011 games drwxr-xr-x. 2 root root 4096 Sep 23 2011 include drwxr-xr-x. 3 spark spark 4096 Mar 23 23:33 jdk drwxr-xr-x. 2 root root 4096 Sep 23 2011 lib drwxr-xr-x. 2 root root 4096 Sep 23 2011 lib64 drwxr-xr-x. 2 root root 4096 Sep 23 2011 libexec drwxr-xr-x. 2 root root 4096 Sep 23 2011 sbin drwxr-xr-x. 3 spark spark 4096 Mar 24 01:26 scala drwxr-xr-x. 5 root root 4096 Mar 22 17:40 share drwxr-xr-x. 2 root root 4096 Sep 23 2011 src [spark@sparksinglenode local]$ su root Password: [root@sparksinglenode local]# mkdir hadoop [root@sparksinglenode local]# chown -R spark:spark hadoop/ [root@sparksinglenode local]# ll total 52 drwxr-xr-x. 2 root root 4096 Sep 23 2011 bin drwxr-xr-x. 2 root root 4096 Sep 23 2011 etc drwxr-xr-x. 2 root root 4096 Sep 23 2011 games drwxr-xr-x. 2 spark spark 4096 Mar 24 01:38 hadoop drwxr-xr-x. 2 root root 4096 Sep 23 2011 include drwxr-xr-x. 3 spark spark 4096 Mar 23 23:33 jdk drwxr-xr-x. 2 root root 4096 Sep 23 2011 lib drwxr-xr-x. 2 root root 4096 Sep 23 2011 lib64 drwxr-xr-x. 2 root root 4096 Sep 23 2011 libexec drwxr-xr-x. 2 root root 4096 Sep 23 2011 sbin drwxr-xr-x. 3 spark spark 4096 Mar 24 01:26 scala drwxr-xr-x. 5 root root 4096 Mar 22 17:40 share drwxr-xr-x. 2 root root 4096 Sep 23 2011 src [root@sparksinglenode local]#

3、解压hadoop文件
[spark@sparksinglenode hadoop]$ tar -zxvf hadoop-2.6.0.tar.gz
4、删除解压包,留下解压完成的文件目录
并修改所属的用户组和用户(这是最重要的!)
5、修改环境变量
vim ~./bash_profile 或 vim /etc/profile
配置在这个文件~/.bash_profile,或者也可以,配置在那个全局的文件里,也可以哟。/etc/profile。
这里,我vim /etc/profile
[root@sparksinglenode hadoop]# vim /etc/profile

#hadoop export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
6、生效hadoop环境变量
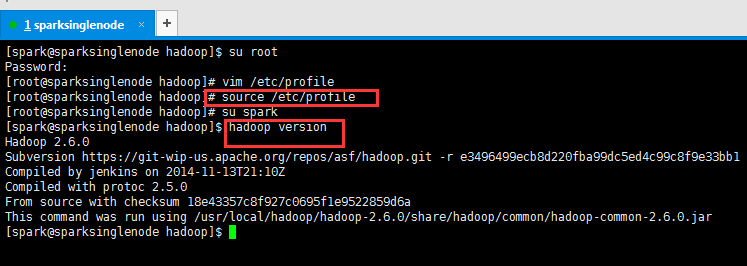
[root@sparksinglenode hadoop]# source /etc/profile [root@sparksinglenode hadoop]# su spark [spark@sparksinglenode hadoop]$ hadoop version Hadoop 2.6.0 Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1 Compiled by jenkins on 2014-11-13T21:10Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /usr/local/hadoop/hadoop-2.6.0/share/hadoop/common/hadoop-common-2.6.0.jar [spark@sparksinglenode hadoop]$
7、配置hadoop

[spark@sparksinglenode hadoop]$ cd hadoop-2.6.0/etc/hadoop/
[spark@sparksinglenode hadoop]$ vim core-site.xml
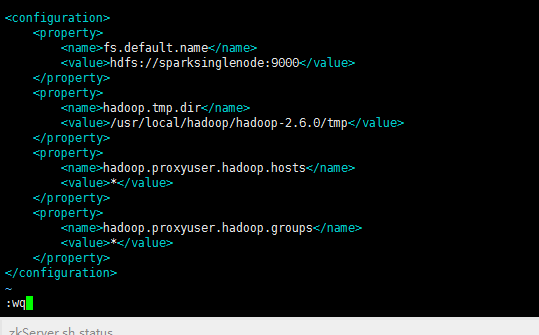
<configuration> <property> <name>fs.default.name</name> <value>hdfs://sparksinglenode:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/hadoop-2.6.0/tmp</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration>

[spark@sparksinglenode hadoop]$ vim hdfs-site.xml
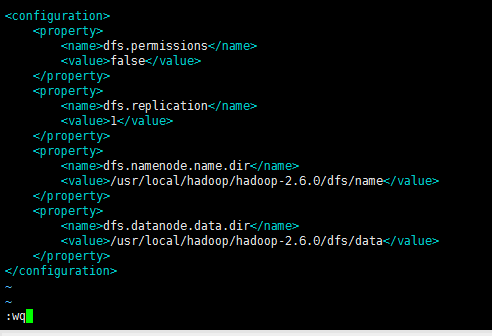
<configuration>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/hadoop-2.6.0/dfs/data</value>
</property>
</configuration>

[spark@sparksinglenode hadoop]$ cp mapred-site.xml.template mapred-site.xml
[spark@sparksinglenode hadoop]$ vim mapred-site.xml

<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>

[spark@sparksinglenode hadoop]$ vim yarn-site.xml
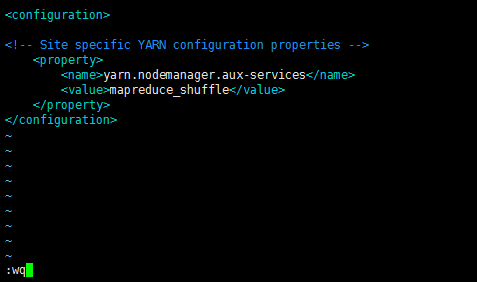
<configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>

[spark@sparksinglenode hadoop]$ vim hadoop-env.sh
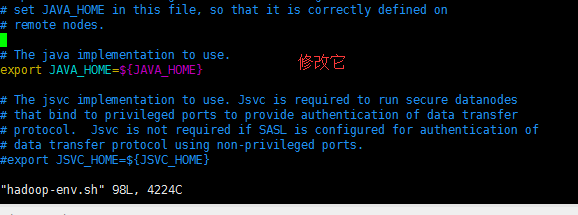
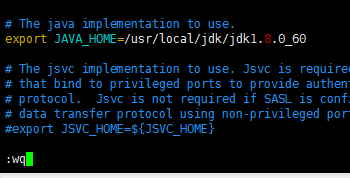
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60

[spark@sparksinglenode hadoop]$ cat slaves

sparksinglenode
8、新建配置文件里牵扯到目录
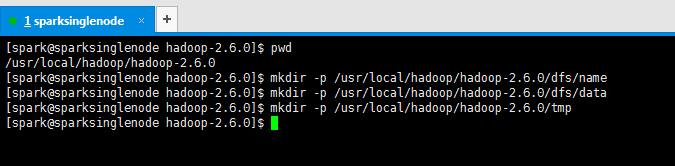
[spark@sparksinglenode hadoop-2.6.0]$ pwd /usr/local/hadoop/hadoop-2.6.0 [spark@sparksinglenode hadoop-2.6.0]$ mkdir -p /usr/local/hadoop/hadoop-2.6.0/dfs/name [spark@sparksinglenode hadoop-2.6.0]$ mkdir -p /usr/local/hadoop/hadoop-2.6.0/dfs/data [spark@sparksinglenode hadoop-2.6.0]$ mkdir -p /usr/local/hadoop/hadoop-2.6.0/tmp
9、hadoop的格式化
在单节点(sparksinglenode)的hadoop的安装目录下,进行如下命令操作
./bin/hadoop namenode -format
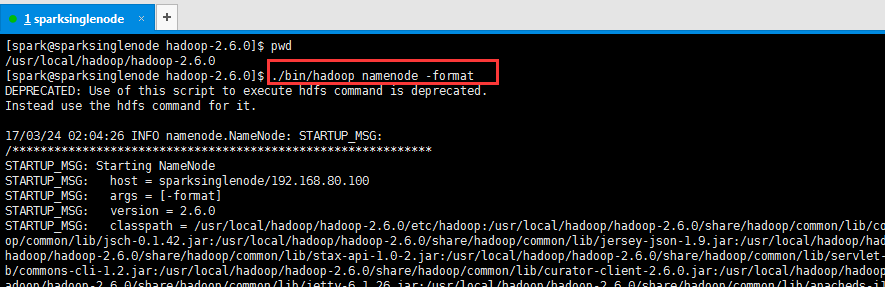
[spark@sparksinglenode hadoop-2.6.0]$ pwd /usr/local/hadoop/hadoop-2.6.0 [spark@sparksinglenode hadoop-2.6.0]$ ./bin/hadoop namenode -format
10、启动hadoop
sbin/start-all.sh

[spark@sparksinglenode hadoop-2.6.0]$ sbin/start-all.sh
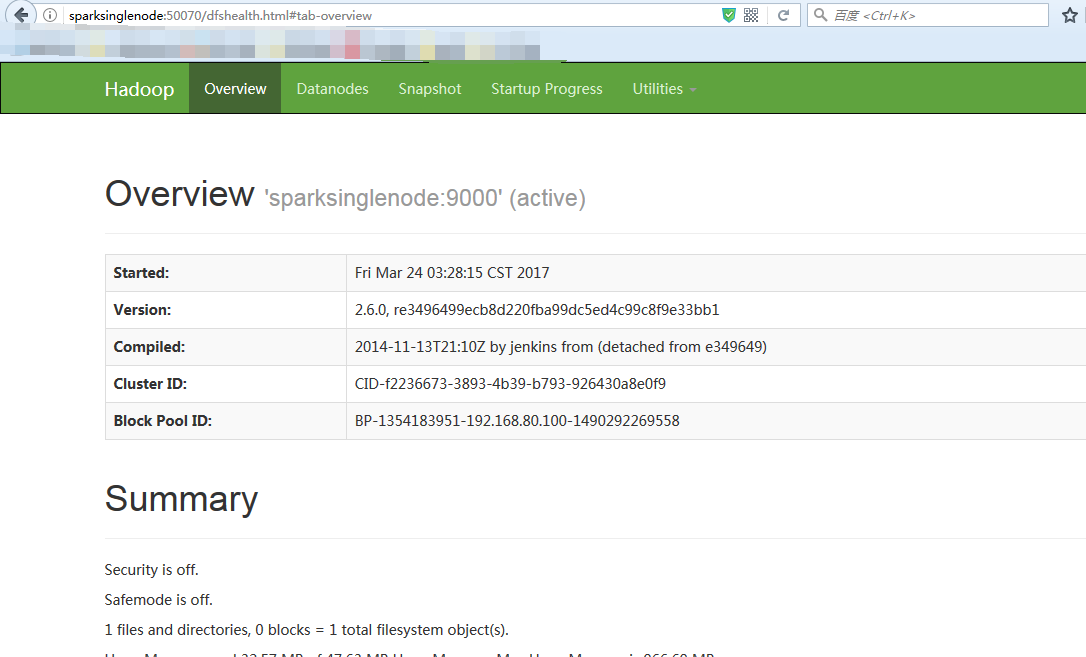
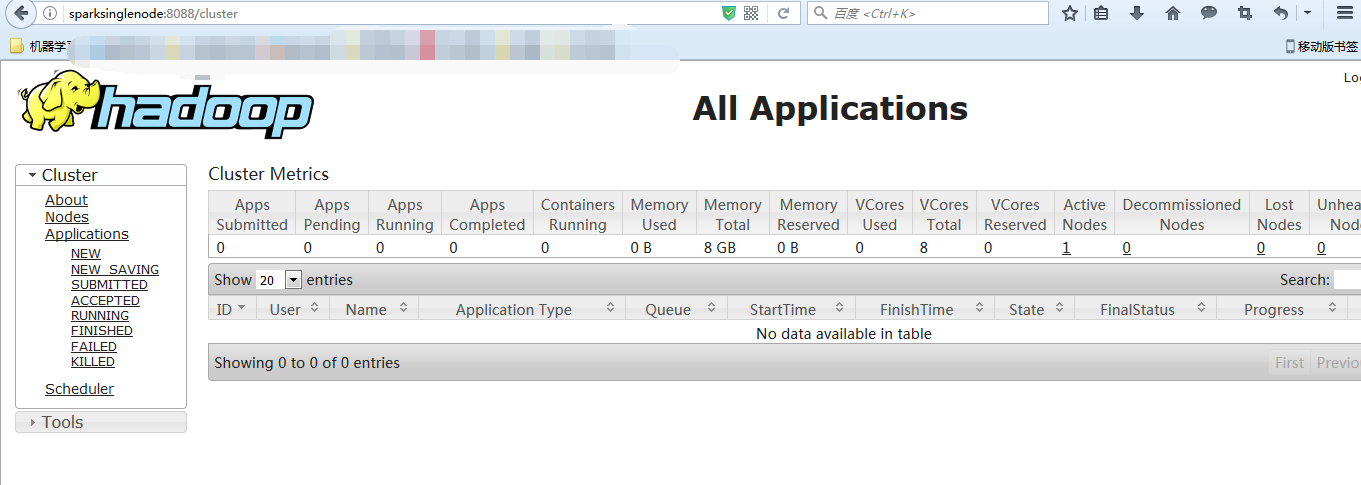
11、开启hadoop的web ui界面,来验证下。
http://sparksinglenode:50070/ 。如果出现50070端口无法访问,则如下
hadoop 50070 无法访问问题解决汇总
五、安装spark
spark-1.6.1-bin-hadoop2.6.tgz ---------------------------------------------- /usr/loca/spark/spark-1.6.1-bin-hadoop2.6
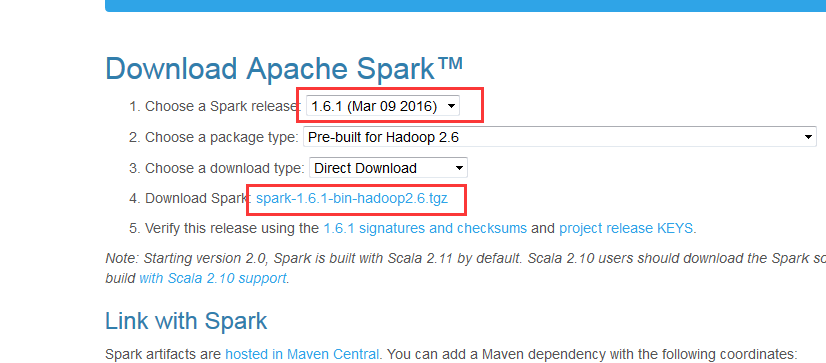
1、spark的下载
这个去官网。很简单!
http://spark.apache.org/downloads.html
http://d3kbcqa49mib13.cloudfront.net/spark-1.6.1-bin-hadoop2.6.tgz

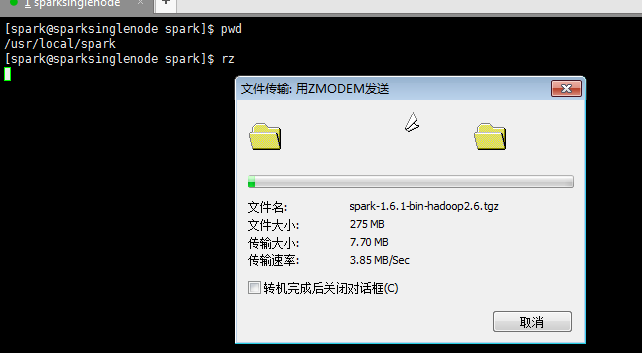
2、spark-1.6.1-bin-hadoop2.6.tgz的上传
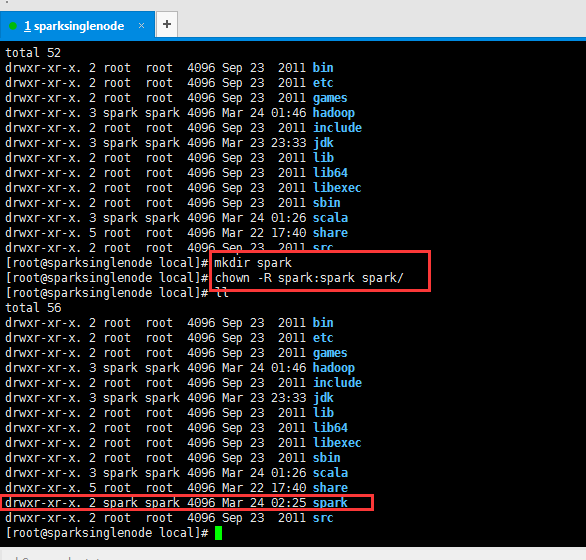
[root@sparksinglenode local]# mkdir spark
[root@sparksinglenode local]# chown -R spark:spark spark/
3、解压spark文件
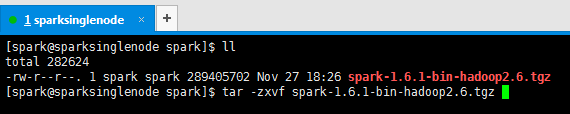
[spark@sparksinglenode spark]$ tar -zxvf spark-1.6.1-bin-hadoop2.6.tgz
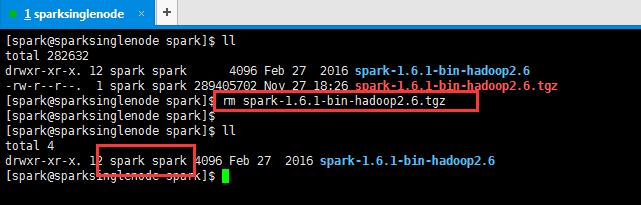
4、删除解压包,留下解压完成的文件目录
并修改所属的用户组和用户(这是最重要的!)
5、修改环境变量
vim ~./bash_profile 或 vim /etc/profile
配置在这个文件~/.bash_profile,或者也可以,配置在那个全局的文件里,也可以哟。/etc/profile。
这里,我vim /etc/profile
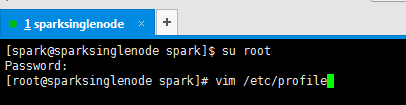
[spark@sparksinglenode spark]$ su root
Password:
[root@sparksinglenode spark]# vim /etc/profile

#spark export SPARK_HOME=/usr/local/spark/spark-1.6.1-bin-hadoop2.6 export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
6、生效spark环境变量
[root@sparksinglenode spark]# source /etc/profile
7、spark配置文件
其实,只要把spark的安装包解压好,就已经安装好了最简易的spark。因为,它自身带有集群环境。
带你认识spark安装包的目录结构

[spark@sparksinglenode conf]$ cp slaves.template slaves
[spark@sparksinglenode conf]$ vim slaves
进入之后,将localhost改为sparksinglenode
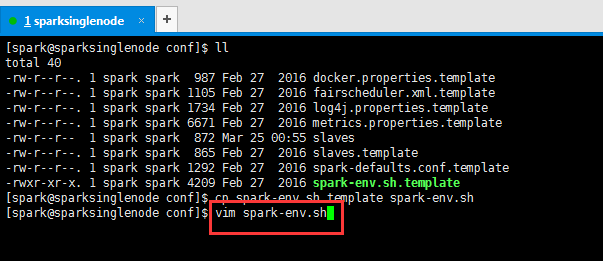
[spark@sparksinglenode conf]$ cp spark-env.sh.template spark-env.sh
[spark@sparksinglenode conf]$ vim spark-env.sh

export JAVA_HOME=/usr/local/jdk/jdk1.8.0_60 export SCALA_HOME=/usr/local/scala/scala-2.10.5 export HADOOP_HOME=/usr/local/hadoop/hadoop-2.6.0 export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-2.6.0/etc/hadoop export SPARK_MASTER_IP=sparksinglenode export SPARK_WORKER_MERMORY=2G
六、启动集群
1、在haoop的安装目录下,启动hadoop集群。
/usr/local/hadoop/hadoop-2.6.0下,执行./sbin/start-all.sh
或,在任何路径下,$HADOOP_HOME/sbin/start-all.sh
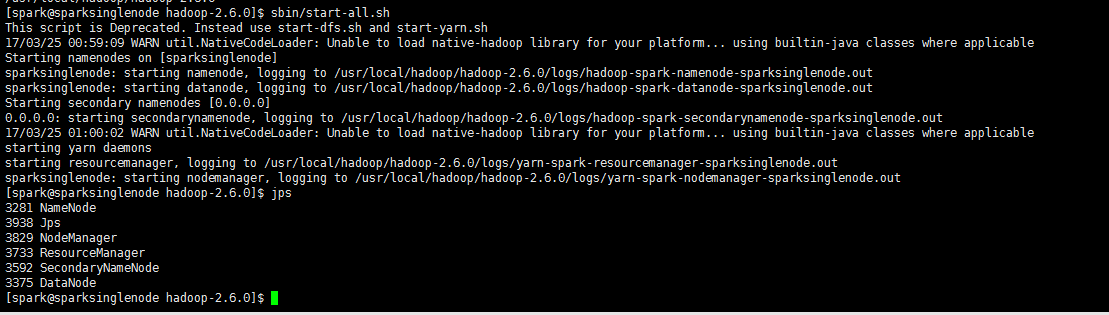
2、在spark的安装目录下,启动spark集群。
/usr/local/spark/spark-1.6.1-bin-hadoop2.6下,执行./sbin/start-all.sh
或, 在任何路径下,执行 $SPARK_HOME/sbin/start-all.sh
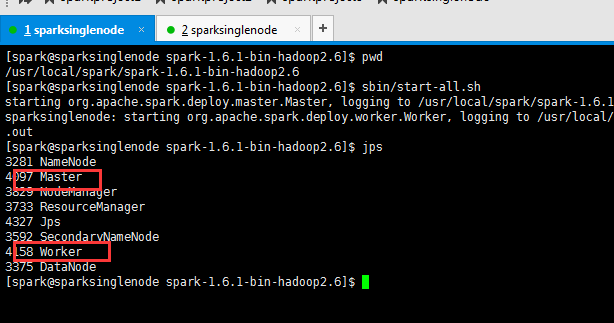
八、查看页面
进入hadoop的hdfs的web页面。访问http://sparksinglenode:50070 (安装之后,立即可以看到)
进入hadoop的yarn的web页面。访问http://sparksinglenode:8088 (安装之后,立即可以看到)
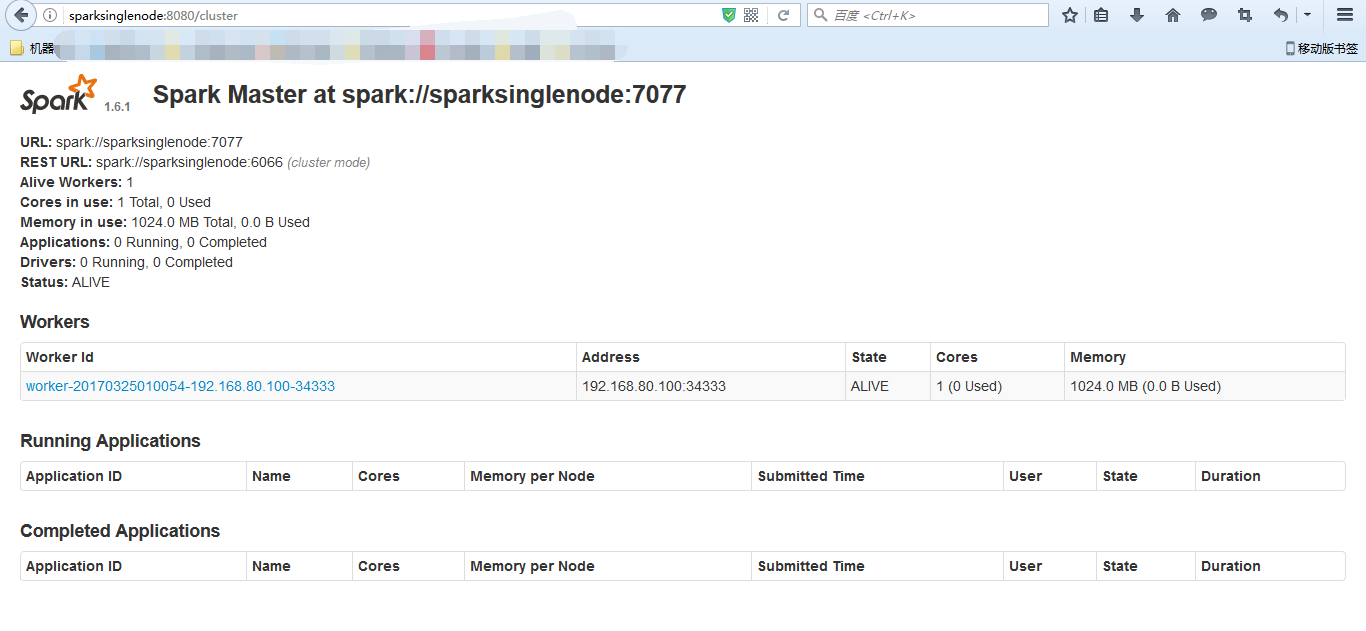
进入spark的web页面。访问 http://sparksinglenode:8080 (安装之后,立即可以看到)
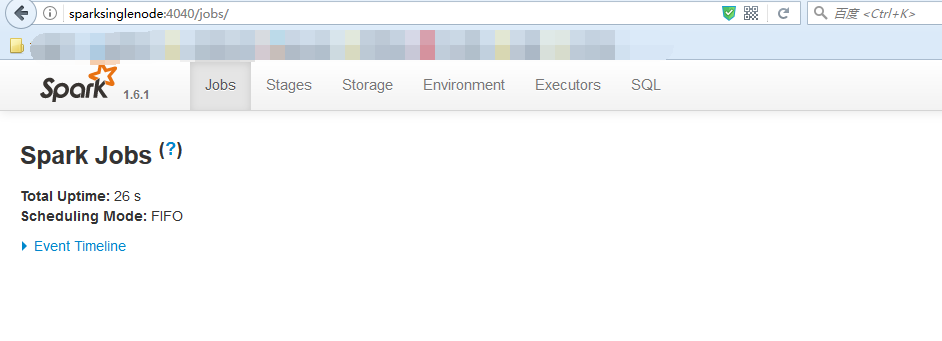
进入spark的shell的web页面。访问http//:sparksinglenode:4040 (需开启spark shell)

成功!
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()




打开百度App,扫码,精彩文章每天更新!欢迎关注我的百家号: 九月哥快讯