CPU和GPU
我们讲讲GPU和CPU是什么,而且为什么深度学习使用GPU会快。

上图最直观的就是CPU的浮点运算能力比显卡差很多,但是显卡的显存不会很大,32G其实也就封顶了,但是CPU的内存可以一直叠加。
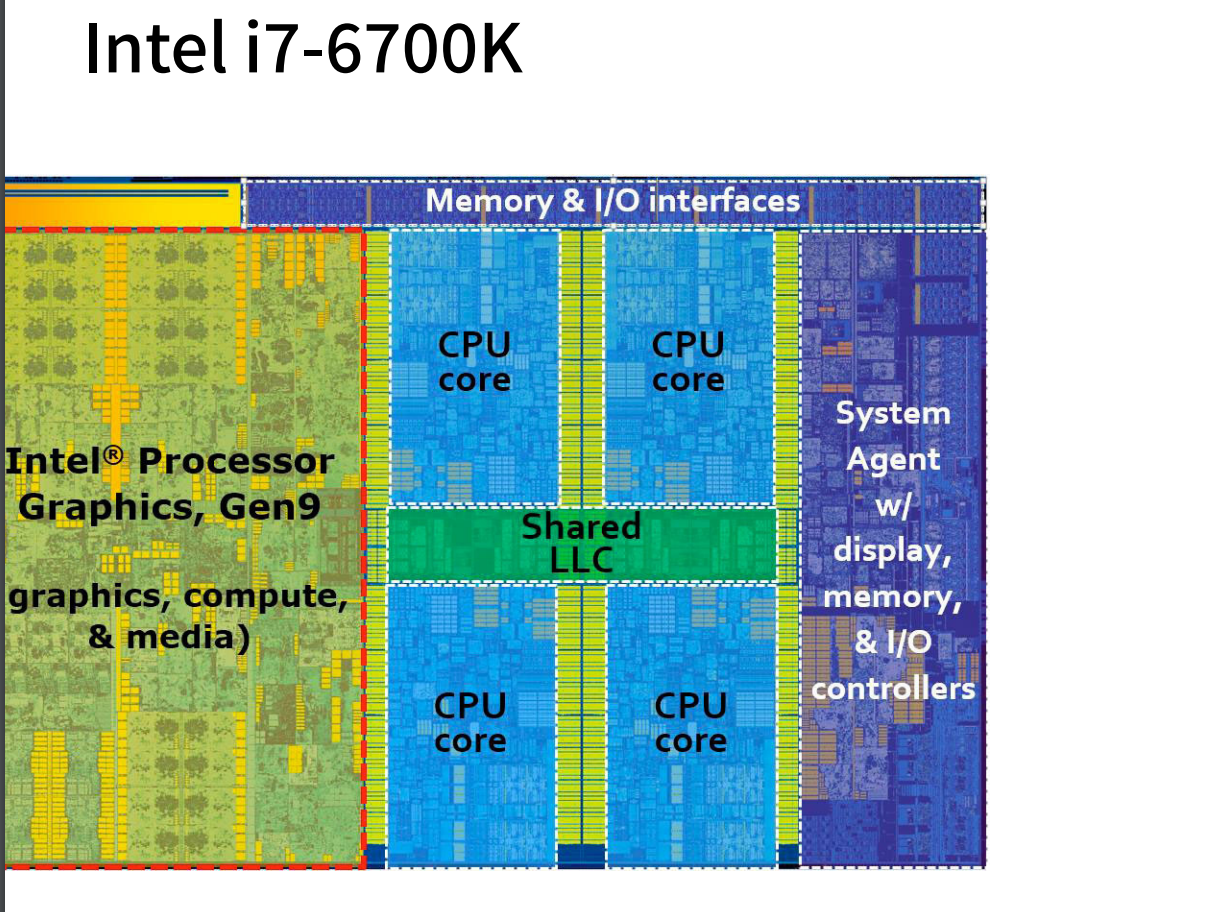


物理核只有一个,但是可以有2个超线程。就是市面上很多说的4核8线程。
超线程对于有IO等待的任务还是有用的,增加并行度。但是对于深度学习这种计算密集的,实际上超线程并不会有提升,因为超线程是共享的寄存器,计算密集型如果一个线程把cache占满了,那么另外一个线程也是只能等着。

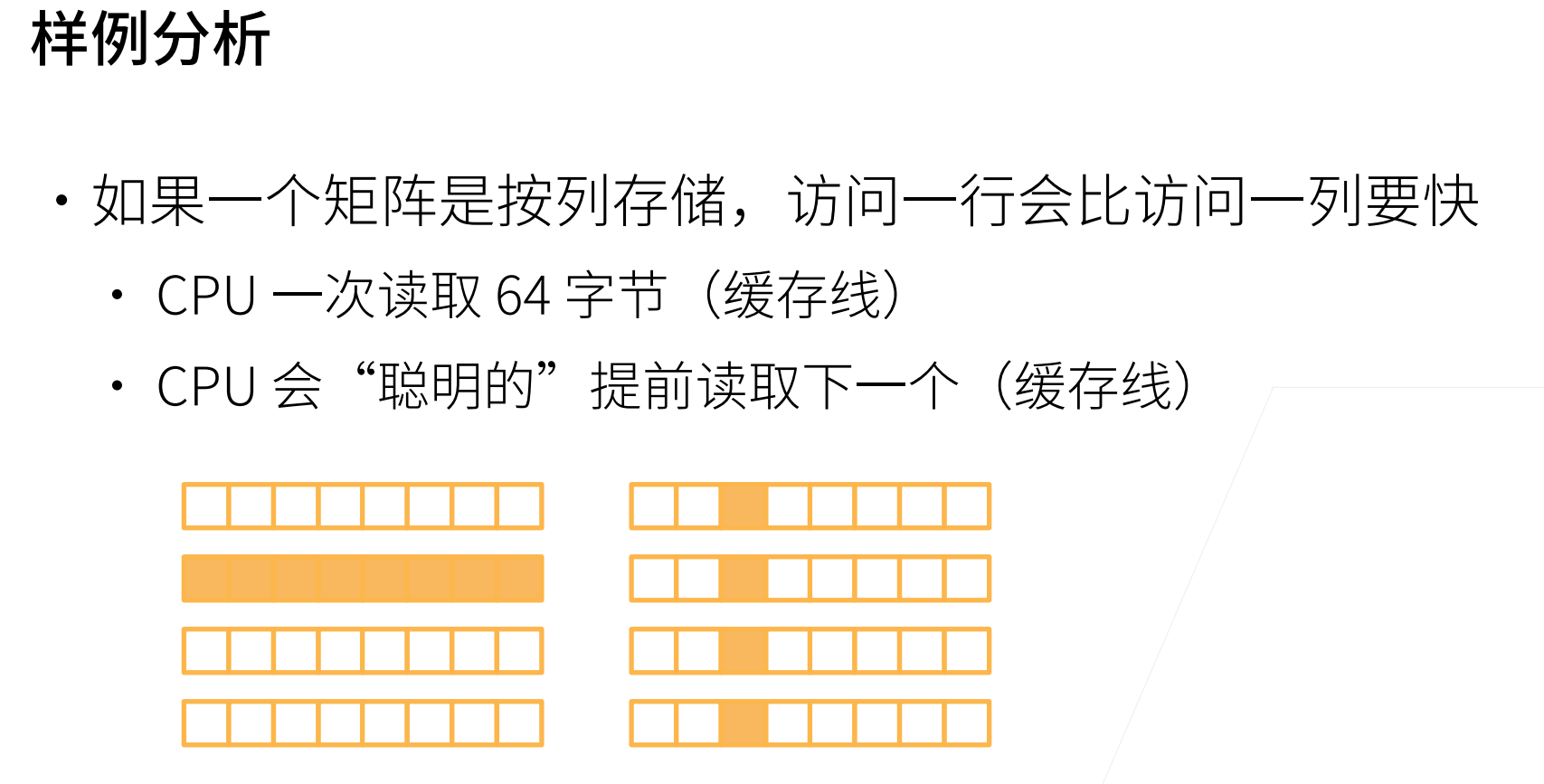
上面关于向量的计算,左边会比右面(numpy)会慢很多。实际上会有慢个几百倍。
左边每次计算一次都要调用一次资源,python资源调动的开销还是挺大的,
但是这个加法运算是容易在Cpp中进行并行的。
CPU性能的提升就是一个保证cache的稳定性,还有一个就是尽量的利用多核。

上面一个方框可以认为是一个“大核”,其中的每个绿点可以看做是一个计算单元,在每个计算单元都可以开一个计算线程。也就是GPU是可以开出上千个线程。
就算GPU每个计算单元算的比CPU慢,但是人家数量多,总体的计算量还是远高于CPU的。

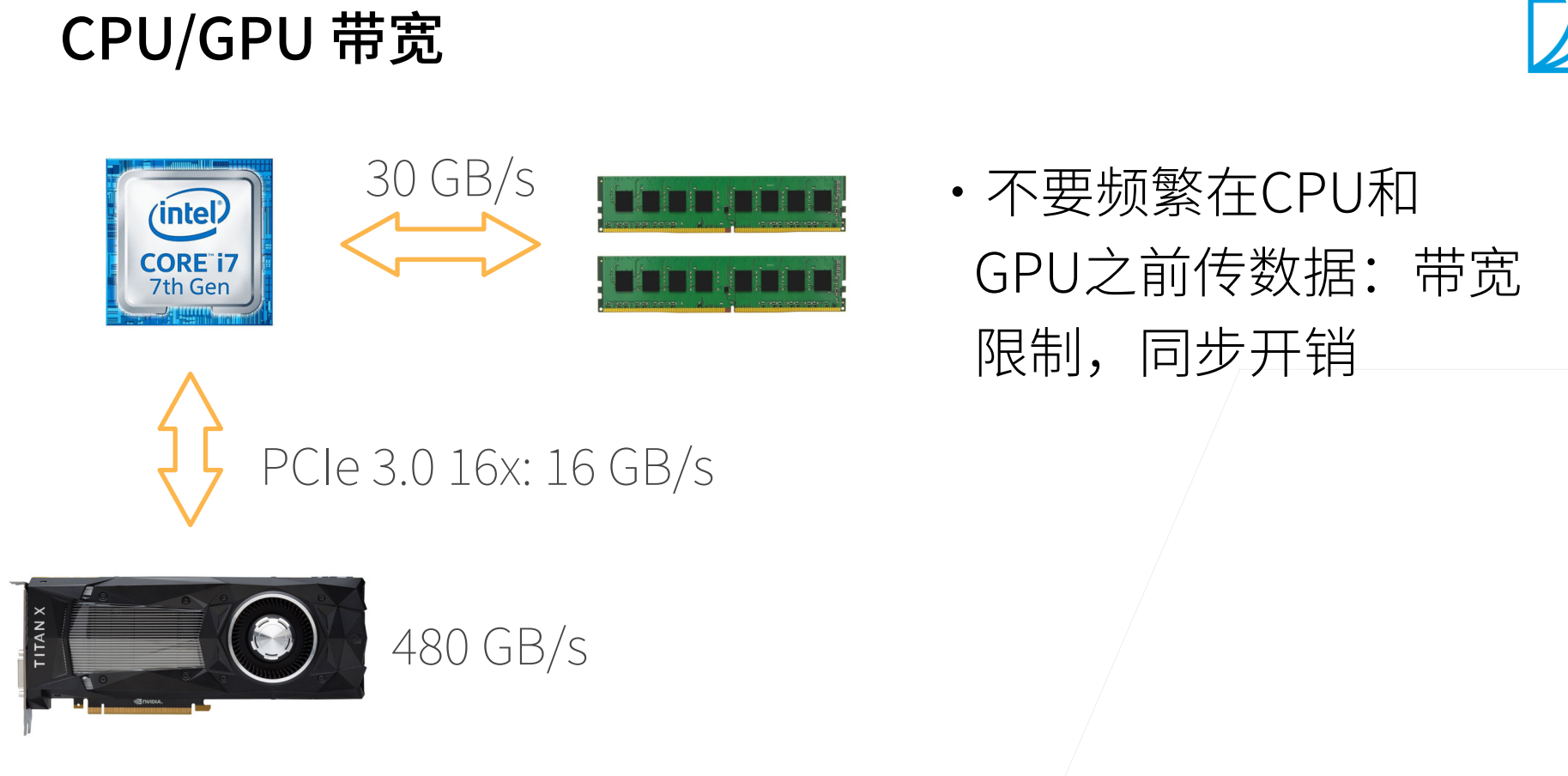
计算的峰值很难达到很大程度与内存的带宽有关,计算的再快,来不及读取,其实也是白费的。
GPU通过多核和高速带宽来实现高速的计算。
显存都是高带宽的内存,这个是很贵的。
GPU基本是没有逻辑控制单元的,就是存在大量的计算核,所以GPU的控制流处理能力很差。




QA
- 如果要提高泛化性,就有可能要增加数据?那么关于调参呢?
在其他条件都不变的情况下,增加数据确实是提高泛化性最直接的方法。当然数据的质量才是关键,如果找了一堆相似的图片,那么再多的图片其实也是没有效果的。
沐神建议是可以调参,但是不要过度调参,因为过度调参的话,可能只能fit到当前的数据。
- LLC是什么?
last level cache,就是直接和内存交换的那一级的缓存,基本的性能瓶颈也是在这里。
- 研一刚进入科研,是一直看论文吗?代码要怎么练习才能复现论文?
首先80%的论文是不能复现的。而且如果要复现一篇论文,你要理解论文中的每一句话,而且作者有把里面的关键细节给写出来。
但是很多时候你不用搞得那么复杂,作者可能会放代码,别人可能也会复现代码,你可以去研究别人的代码。而且代码和论文多多少少有些不一样,很多实现的技术细节是不一样的。代码也要去看懂每一句话,然后去琢磨这个细节到底是干嘛的,
网站:paper with code
- 分布式和高性能的差别是什么?
分布式主要考虑的容灾的问题,就是一台服务器挂了之后应该如何应对。
高性能一般不太会去考虑容灾的问题,更加关注的性能的问题。
- resnet只能用在图像领域吗?文本可以用吗?
resnet不能用在文本上,但是我们后面将讲如何使用卷积来处理文本。
- Xavier初始化和BN可以一起用么?
是可以一起用的,只不过说的是BN不要和dropout一起使用。
- 看了很多目标检测的paper,但是现在打比赛就是一些简单集成,数据增强,感觉没有什么模型原创性,怎么才能有更多的模型改造和优化能力?
打比赛可以打一打,但是不会学到太多东西...