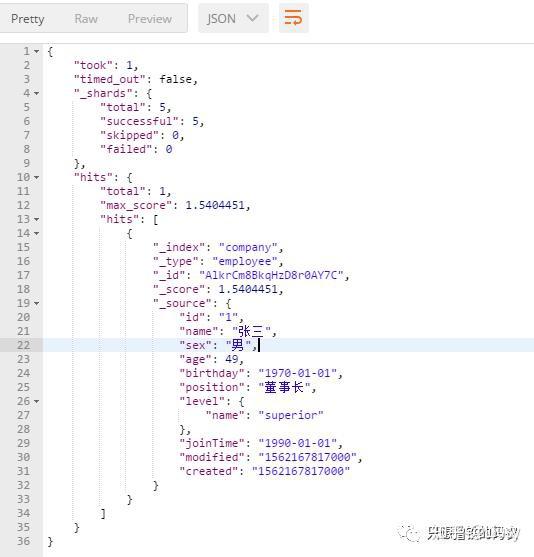
对es查询的索引的company,其有如下字段,下面是一个示例数据
"id": "1", //id
"name": "张三",//姓名
"sex": "男",//性别
"age": 49,//年龄
"birthday": "1970-01-01",//生日
"position": "董事长",//职位
"joinTime": "1990-01-01",//入职时间,日期格式
"modified": "1562167817000",//修改时间,毫秒
"created": "1562167817000" //创建时间,毫秒下面的搜索都会将关系型数据库语句转换成es的搜索api以及参数。
主要是用post方式,用DSL(结构化查询)语句进行搜索。
一、查询
1、简单搜索
【sql】
select * from company
【ES】有两种方式
1、GET http://192.168.197.100:9200/company/_search
2、POST http://192.168.197.100:9200/company/_search
{
"query":{"match_all":{}}
}2、精确匹配(不对查询文本进行分词)
【sql】
select * from company where name='张三'
【ES】
POST http://192.168.197.100:9200/company/_search
{
"query":{
"term":{"name.keyword":"张三"}
}
}term是用于精确匹配的,类似于sql语句中的“=”,因为“name”字段用的是standard默认分词器,其会将“张三”分成“张”和“三”,并不会匹配姓名为“张三”的人,而name.keyword可以让其不会进行分词。
也可以是terms,这个可以用多个值去匹配一个字段,例如
【sql】
select * from company where name in ('张三','李四')
【ES】
POST http://192.168.197.100:9200/company/_search
{
"query": {
"terms": {
"name.keyword": ["张三", "李四"]
}
}
}3、模糊匹配
【sql】
select * from company where name like '%张%'
【ES】
POST http://192.168.197.100:9200/company/_search
{
"query": {
"match": {
"name": "张"
}
}
}上述查询会查出姓名中带有“张”字的文档
4、分页查询
【sql】
select * from company limit 0,10
【ES】
POST http://192.168.197.100:9200/company/_search
{
"from":0,
"size":10
}【注意】from+size不能大于10000,也可以进行修改,但不建议这么操作,因为es主要分片模式,其会在每个分片都会执行一样的查询,然后再进行汇总排序,如果数据太大,会撑爆内存。例如每个分片都查询出10000条,总共5个分片,最后就会进行50000条数据的排序,最后再取值。
5、范围查询并进行排序
【sql】
select * from company where age>=10 and age<=50
【ES】
POST http://192.168.197.100:9200/company/_search
{
"query":{
"range":{
"age":{
"gte":10,
"lte":50
}
}
},
"sort":{
"age":{
"order":"desc"
}
}
}范围查询是range,有四种参数
(1)gte:大于等于
(2)gt:大于
(3)lte:小于等于
(4)lt:小于
排序是sort,降序是desc,升序是asc,可以有多个排序字段
6、多字段匹配查询
【sql】
select * from company where sex like '%男%' or name like '%男%'
【ES】
POST http://192.168.197.100:9200/company/_search
{
"query":{
"multi_match":{
"query":"男",
"fields":["name","sex"]
}
}
}7、bool查询(结构化查询)
结构化查询主要有三块,分别是must,should,must_not,filter
(1)must:里面的条件都是“并”关系,都匹配
(2)should:里面的条件都是“或”关系,有一个条件匹配就行
(3)must_not:里面的条件都是“并”关系,都不能匹配
(4)filter:过滤查询,不像其它查询需要计算_score相关性,它不进行此项计算,故比query查询快
例如:
条件:
年龄在10到50,性别是男
性别一定不能是女
id是1~8的或者职位带有“董”字的
【sql】
select * from company where (age>=10 and age=50 and sex="男")
and (sex!="女")
and (id in (1,2,3,4,5,6,7,8) or position like '%董%')
and departments in ('市场部')
【ES】
POST http://192.168.197.100:9200/company/_search
{
"query":{
"bool":{
"must":[
{"term":{"sex":"男"}},
{"range":{
"age":{
"gte":10,
"lt":50
}
}}
],
"must_not":[
{"term":{"sex":"女"}}
],
"should":[
{"terms":{"id":[1,2,3,4,5,6,7,8]}},
{"match":{"position":"董"}}
],
"filter":[
{"match":{"departments.keyword":"市场部"}}
]
}
}
}另外,bool查询是可以嵌套的,也就是must、must_not、should、filter里面还可以嵌套一个完整的bool查询。
8、通配符查询
?:只匹配一个字符
*:匹配多个字符
【sql】
select * from company where departments like '%部'
【ES】
POST http://192.168.197.100:9200/company/_search
{
"query":{
"wildcard":{
"departments.keyword":"*部"
}
}
}9、前缀查询
【sql】
select * from company where departments like '市%'
【ES】
POST http://192.168.197.100:9200/company/_search
{
"query":{
"match_phrase_prefix":{
"departments.keyword":"市"
}
}
}10、查询空值(null)
比如我添加一个文档,里面没有sex字段或者添加的时候sex字段为null,这种情况该怎么进行查询呢?
//添加文档
POST http://192.168.197.100:9200/company/_doc
//没有sex字段的文档
{
"id": "1",
"name": "张十",
"age": 54,
"birthday": "1960-01-01",
"position": "程序员",
"joinTime": "1980-01-01",
"modified": "1562167817000",
"created": "1562167817000"
}
//sex字段值为null的文档
{
"id": "1",
"name": "张十一",
"age": 64,
"sex":null,
"birthday": "1960-01-01",
"position": "程序员",
"joinTime": "1980-01-01",
"modified": "1562167817000",
"created": "1562167817000"
}这两种情况的查询是一样的,都是用exists查询匹配,例如:下面的查询会匹配出上述添加的两个文档。
【sql】
select * from company where sex is null
【ES】
POST http://192.168.197.100:9200/company/_search
{
"query":{
"bool":{
"must_not":[
{"exists":
{"field":"sex"}
}
]
}
}
}二、过滤(在es5之后被去除了)
过滤跟查询很相似,都是用来查询数据,只不过过滤会维系一个缓存数组,数组里面记录了匹配的文档,比如一个索引下面有两个文档,进行过滤,一个匹配,一个不匹配,那么数组是这样的[1,0],匹配的文档为1。
在频繁查询的时候,建议用过滤而不是索引。
过滤跟查询的请求体基本相似,只不过多嵌套了一层filtered。
例如:
【sql】
select * from company where departments like '%市%'
【ES】
POST http://192.168.197.100:9200/company/_search
{
"query":{
"filtered":{
"filter":{
"match":{
"departments.keyword":"市"
}
}
}
}
}三、聚合
聚合允许使用者对es文档进行统计分析,类似与关系型数据库中的group by,当然还有很多其他的聚合,例如取最大值、平均值等等。
语法如下:
POST http://192.168.197.100:9200/company/_search
{
"aggs": {
"NAME": { //指定结果的名称
"AGG_TYPE": { //指定具体的聚合方法,
TODO: //# 聚合体内制定具体的聚合字段
}
}
TODO: //该处可以嵌套聚合
}
}聚合分析功能主要有指标聚合、桶聚合、管道聚合和矩阵聚合,常用的有指标聚合和桶聚合,本文主要看一下指标聚合和桶聚合怎么使用。
1、指标聚合
(1)对某个字段取最大值max
【sql】
select max(age) from company
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"max_age":{
"max":{"field":"age"}
}
},
"size":0 //size=0是为了只看聚合结果
}结果如下:
{
"aggregations": {
"max_age": {
"value": 64
}
}
}(2)对某个字段取最小值min
【sql】
select min(age) from company
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"min_age":{
"min":{"field":"age"}
}
},
"size":0
}结果如下:
{
"aggregations": {
"min_age": {
"value": 1
}
}
}(3)对某个字段计算总和sum
【sql】
select sum(age) from company
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"sum_age":{
"sum":{"field":"age"}
}
},
"size":0
}结果如下:
{
"aggregations": {
"sum_age": {
"value": 315
}
}
}(4)对某个字段的值计算平均值
【sql】
select avg(sex) from company
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"age_avg":{
"avg":{"field":"age"}
}
},
"size":0
}结果如下:
{
"aggregations": {
"age_avg": {
"value": 35
}
}
}(5)对某个字段的值进行去重之后再取总数
【sql】
select count(distinct(sex)) from company
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"sex_distinct":{
"cardinality":{"field":"sex"}
}
},
"size":0
}结果如下:
{
"aggregations": {
"sex_distinct": {
"value": 2
}
}
}(6)stats聚合,对某个字段一次性返回count,max,min,avg和sum五个指标
【sql】
select count(distinct age),sum(age),avg(age),max(age),min(age) from company
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"age_stats":{
"stats":{"field":"age"}
}
},
"size":0
}结果如下:
{
"aggregations": {
"age_stats": {
"count": 9,
"min": 1,
"max": 64,
"avg": 35,
"sum": 315
}
}
}(7)extended stats聚合,比stats聚合高级一点,多返回平方和、方差、标准差、平均值加/减两个标准差的区间
【sql】
--这个的sql不会写,数学专业的人公式都忘了,耻辱
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"age_extended_stats":{
"extended_stats":{"field":"age"}
}
},
"size":0
}结果如下:
{
"aggregations": {
"age_extended_stats": {
"count": 9,
"min": 1,
"max": 64,
"avg": 35,
"sum": 315,
"sum_of_squares": 13857,
"variance": 314.6666666666667,
"std_deviation": 17.73884626086676,
"std_deviation_bounds": {
"upper": 70.47769252173353,
"lower": -0.4776925217335233
}
}
}
}(8)percentiles聚合,对某个字段的值进行百分位统计
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"age_percentiles":{
"percentiles":{"field":"age"}
}
},
"size":0
}结果如下:
{
"aggregations": {
"age_percentiles": {
"values": {
"1.0": 1,
"5.0": 1,
"25.0": 26,
"50.0": 29,
"75.0": 50.25,
"95.0": 64,
"99.0": 64
}
}
}
}(9)value count聚合,统计文档中有某个字段的文档数量
【sql】
select sum(case when sex is null then 0 else 1 end) from company
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"sex_value_count":{
"value_count":{"field":"sex"}
}
},
"size":0
}结果如下:总共有8个文档,我在之前添加了两个没有sex字段的文档
【sql】
select sum(case when sex is null then 0 else 1 end) from company
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"sex_value_count":{
"value_count":{"field":"sex"}
}
},
"size":0
}2、桶聚合
桶聚和相当于sql中的group by语句。
(1)terms聚合,分组统计
【sql】
select sex,count(1) from company group by sex
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"sex_groupby":{
"terms":{"field":"sex"}
}
},
"size":0
}结果如下:
{
"aggregations": {
"sex_groupby": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "男",
"doc_count": 5
},
{
"key": "女",
"doc_count": 1
}
]
}
}
}(2)可以在terms分组下再对其他字段进行其他聚合
【sql】
SELECT name,count(1),AVG(age) from company group by name
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"sex_groupby":{
"terms":{"field":"sex"},
"aggs":{
"avg_age":{
"avg":{"field":"age"}
}
}
}
},
"size":0
}结果如下:
{
"aggregations": {
"sex_groupby": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "男",
"doc_count": 5,
"avg_age": {
"value": 33.8
}
},
{
"key": "女",
"doc_count": 1,
"avg_age": {
"value": 27
}
}
]
}
}
}(3)filter聚合,过滤器聚合,对符合过滤器中条件的文档进行聚合
【sql】
select sum(age) from company where sex = '男'
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"sex_filter":{
"filter":{"term":{"sex":"男"}},
"aggs":{
"sum_age":{
"sum":{"field":"age"}
}
}
}
},
"size":0
}结果如下:
{
"aggregations": {
"sex_filter": {
"doc_count": 5,
"sum_age": {
"value": 169
}
}
}
}(4)filters多过滤器聚合
【sql】
SELECT name,count(1),sum(age) from company group by name
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"sex_filter":{
"filters":{
"filters":[{"term":{"sex":"男"}},{"term":{"sex":"女"}}]
},
"aggs":{
"sum_age":{
"sum":{"field":"age"}
}
}
}
},
"size":0
}结果如下:
{
"aggregations": {
"sex_filter": {
"buckets": [
{
"doc_count": 5,
"sum_age": {
"value": 169
}
},
{
"doc_count": 1,
"sum_age": {
"value": 27
}
}
]
}
}
}(6)range范围聚合,用于反映数据的分布情况
【sql】
SELECT sum(case when age<=30 then 1 else 0 end),
sum(case when age>30 and age<=50 then 1 else 0 end),
sum(case when age>50 then 1 else 0 end)
from company
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"age_range":{
"range":{
"field":"age",
"ranges":[
{"to":30},
{"from":30,"to":50},
{"from":50}
]
}
}
},
"size":0
}结果如下:
{
"aggregations": {
"age_range": {
"buckets": [
{
"key": "*-30.0",
"to": 30,
"doc_count": 5
},
{
"key": "30.0-50.0",
"from": 30,
"to": 50,
"doc_count": 2
},
{
"key": "50.0-*",
"from": 50,
"doc_count": 2
}
]
}
}
}(7)missing聚合,空值聚合,可以统计缺少某个字段的文档数量
【sql】
SELECT count(1) from company where sex is null
【ES】
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"missing_sex":{
"missing":{"field":"sex"}
}
},
"size":0
}结果如下:
{
"aggregations": {
"missing_sex": {
"doc_count": 4
}
}
}这个也可以用filter过滤器查询,例如:得到的结果是一样的
POST http://192.168.197.100:9200/company/_search
{
"aggs":{
"missing_sex":{
"filter":{
"bool":{
"must_not":[
{"exists":{"field":"sex"} }
]
}
}
}
},
"size":0
}