(3)在逻辑回归中的应用。
由于交叉熵是衡量两个分布之间的相似度,在逻辑回归中,首先数据集真实的分布是p,通过逻辑回归模型预测出来的结果对应的分布是q,此时交叉熵在这里就是衡量预测结果q与真实结果p之间的差异程度,称之为交叉熵损失函数。具体如下:
假设,对应两分类的逻辑回归模型logistic regression来说,他的结果有两个0或者1,在给定预测向量x,通过logistics regression回归函数g(z)=1/(1+e-z),则真实结果y=1,对应预测结果y'=g(wx);真实结果y=0,对应预测结果y'=1-g(wx);以上就是通过g(wx)和1-g(wx)来描述原数据集0-1分布。根据交叉熵的定义可知:
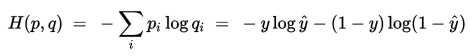
上式是针对测试集一个样本得到的交叉熵。若测试集有N个样本,对应的交叉熵损失函数表示方式如下:
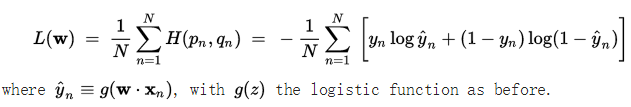
1、交叉熵的定义:
在信息论中,交叉熵是表示两个概率分布p,q,其中p表示真实分布,q表示非真实分布,在相同的一组事件中,其中,用非真实分布q来表示某个事件发生所需要的平均比特数。从这个定义中,我们很难理解交叉熵的定义。下面举个例子来描述一下:
假设现在有一个样本集中两个概率分布p,q,其中p为真实分布,q为非真实分布。假如,按照真实分布p来衡量识别一个样本所需要的编码长度的期望为: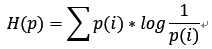
但是,如果采用错误的分布q来表示来自真实分布p的平均编码长度,则应该是: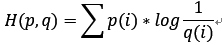
此时就将H(p,q)称之为交叉熵。交叉熵的计算方式如下:
对于离散变量采用以下的方式计算:
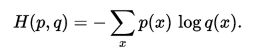
对于连续变量采用以下的方式计算:
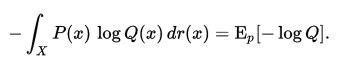
实际上,交叉熵是衡量两个概率分布p,q之间的相似性。这可以子啊特征工程中,用来衡量变量的重要性。
2、交叉熵的应用:
(1)在特征工程中,可以用来衡量两个随机变量之间的相似度
(2)语言模型中(NLP),由于真实的分布p是未知的,在语言模型中,模型是通过训练集得到的,交叉熵就是衡量这个模型在测试集上的正确率。其计算方式如下:
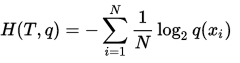
其中,N是表示的测试集的大小,q(x)表示的是事件x在训练集中的概率(在nlp中就是关键词在训练语料中的概率)。