概述:本文主要分析Python的编码格式以及字符串
一、字符编码
群雄割据
计算机早期采用的是ASCII编码,只有127个字符被编码到计算机里。ASCII编码用一个字节(8bit)即可表示。
为了处理自己的语言,各国都制定了自己的编码。如中国的GB2312编码,日本的Shift_JIS编码,韩国的Euc-kr编码等。由于编码格式不统一,免不了有冲突。具体的现象就是显示乱码。
Unicode:四海归一
于是Unicode应运而生。Unicode将所有语言统一到一套编码里,从而解决了乱码问题。
Unicode 最常用的是用两个字节表示一个字符,仅有非常偏僻的字符用到了 4 个字节。
ASCII 编码转为 Unicode 编码,只需在前面补 0 即可。
但 Unicode 也并非完美。如果我们只用到了英语,使用 ASCII 码,一个字节就能搞定。现在改用 Unicode,需要两个字节,而且前面的字节还是全 0,非常浪费。为了解决这个问题,在 Unicode 基础上,又发展出“可变长编码” UTF-8:
1. UTF-8 把一个 Unicode 字符根据不同的数字大小编码成 1-6 个字节;
2. 英文字母被编码为 1 个字节(所以 ASCII 编码可以被看作 UTF-8 编码的一部分,只支持 ASCII 编码的老软件也可以在 UTF-8 编码下继续工作);
3. 汉字被编码为 3 个字节;
4. 非常生僻的字符被编码成 4-6 字节。
计算机系统通用的字符编码工作方式
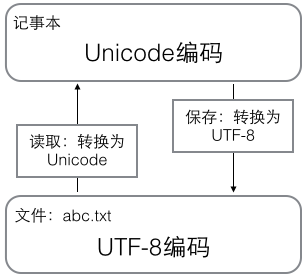
1. 在计算机内存中,统一使用 Unicode 编码;
2. 需要保存到硬盘或需要传输时,转换为 UTF-8 编码;
3. 用编辑器编辑时,从文件读取的 UTF-8 字符被转换为 Unicode 字符,存放在内存里。编辑完成后,再将 Unicode 转换为 UTF-8,保存到文件。
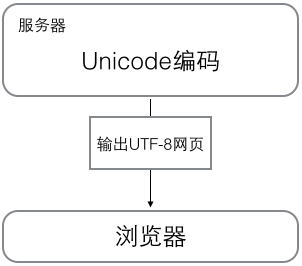
4. 浏览网页时,服务器将动态生成的 Unicode 内容转换为 UTF-8 再传输到浏览器。
二、Python的字符串
Python 3 中,字符串以 Unicode 编码,所以 Python 3 的字符串支持多语言。
编码和字符的相互转换
前文我们提到,字符在计算机内部也是以整数编码保存的,对于每个字符集,整数和编码具有一一映射关系。
Python 中,提供了 ord() 和 chr() 函数来进行编码和字符的相互转换:
>>> ord('勤') 21220 >>> chr(21220) '勤'
如果知道字符的整数编码,还可以用 16 进制来写字符串,格式为 'u十六进制编码'。例如:“勤”的整数编码是 21220,十六进制为 0x52E4。“奋”的整数编码是 22859,十六进制为 0x594B。
>>> 'u52E4u594B' '勤奋'
字符的传输与存储
Python 的字符串(str 类型)在内存中以 Unicode 表示,一个字符对应若干字节。如果要在网络上传输,或存储到磁盘,就要把字符串变为以字节为单位的 bytes。
Python 对 bytes 类型的数据,用带 b 前缀的单引号或双引号表示,如: b = b'ABC' 。要注意:"ABC"才是字符串,b"ABC"虽然和前者内容一样,但每个字符只占用一个字节。
以 Unicode 表示的 str 通过 encode() 方法可以编码为指定的 bytes,传入的参数指定用哪种编码格式。例如: ‘ABC’.encode('ascii')。注意,含有中文的 str 不能用 ASCII 编码,因为超出了范围。在 bytes 中,无法显示为 ASCII 字符的字节,用 x## 表示。
如果我们从网络或磁盘读取字节流,读到的数据就是 bytes。用 decode() 函数可以把 bytes 变为 str,例如: b'ABC'.decode('ascii')。如果bytes中包含无法解码的字节,则会报错。我们可以传入 errors='ignore' 来忽略错误,如: b'xe4xb8xadxff'.decode('utf-8', errors='ignore')
字符串长度
可以用 len() 函数获取 str 包含多少个字符。如果传入的不是 str 而是 bytes 类型,则计算字节数。
# 传入 str >>> len('ABC') 3 >>> len('中文') 2 # 传入 bytes >>> len(b'ABC') 3 >>> len('中文'.encode('utf-8')) 6
由上代码可知,1个中文字符经 UTF-8 编码后,通常占用 3 个字节。
str和bytes转换
我们经常遇到 str 和bytes 的相互转换,为了避免乱码,要始终用 UTF-8 进行转换。
源码中包含中文时,也要指定为 UTF-8 编码。为了保证 Python 解释器读取代码时按 UTF-8 读取,需要在文件开头写上以下两行
#!/usr/bin/env python3 # -*- coding: utf-8 -*-
在文件首部声明使用 UTF-8 编码,并不意味着这个文件就是 UTF-8 编码(它只是告诉 Python 解释器要按 UTF-8 读取文件)。我们必须要设置文本编辑器,使用 UTF-8 without BOM 编码。
输出格式化字符串
在 Python 中,采用的格式化方法和 C 一样,用 % 实现。有几个 %? 占位符,后面就要跟几个变量或者数值,顺序要一一对应。如果只有一个 %?,可以省略后面的括号。
常见的占位符:
| 占位符 | 替换内容 |
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
格式化整数和浮点数可以指定是否补 0,以及整数和小数的位数。
>>> print('%2d-%02d' % (3, 1)) 3-01 >>> print('%.2f' % 3.1415926) 3.14
如果不确定用哪个占位符,那就用 %s 吧,它会把所有数据类型都转换为字符串:
>>> 'Age: %s. Gender: %s' % (25, True) 'Age: 25. Gender: True'
如果字符串中有 % 字符怎么办?此时应用 % 来转义:
>>> 'growth rate: %d %%7' 'growth rate: %d %%7'
除了用 % 占位符来格式化字符串,还可以用字符串的 format() 方法。但这种方式比较麻烦,很少使用,故此处不再赘述。