Block diagram of Position only tile based rendering (PTBR)
2 ARCHITECTURE HIGHLIGHTS
Intel’s on-die integrated processor graphics architecture offers outstanding real time 3D rendering and media performance. In addition, its underlying compute architecture also offers general purpose compute capabilities that delivers up to a teraFLOP performance. The architecture of Intel processor graphics delivers a full complement of high-throughput floating-point and integer compute capabilities, a layered high bandwidth memory hierarchy, and deep integration with on-die CPUs and other on-die SoC devices. While Gen11 will typically ship with 64EUs, there may be different configurations.
Up to a TERAFLOP Performance
Gen11 processor graphics is based on Intel’s 10nm process utilizing the 3rd generation FinFET technology. Additional refinements have been implemented throughout the micro architecture to provide significant performance per watt improvements. Gen11 supports all the major APIs DirectX™*, OpenGL™*, Vulkan™*, OpenCL™* and Metal™*.
Gen11 consists of 64 execution units (EUs) which increases the core compute capability by 2.67x1 over Gen9. Gen11 addresses the corresponding bandwidth needs by improving compression, increasing L3 cache as well as increasing peak memory bandwidth.
In addition to the raw improvements in compute and memory bandwidth increases, Gen11 introduces key new features that enable higher performance by reducing the amount of redundant work.
Coarse pixel shading (CPS)
Coarse pixel shading is a technique that Intel® first described in the seminal 2014 High Performance Graphics Paper “Coarse Pixel Shading.” Games today typically provide mechanism to render at lower resolution and then upscale to selected screen resolution to enable playable frame rates with high DPI screens. This may result in artifacts such as aliasing or jaggies resulting in markedly diminished visual quality.
Coarse pixel shading enables application developers with a new rate control on pixel shading invocations. CPS is better than upscaling because it allows developers to preserve the visibility sampling at the render target resolution while sampling the more slowly varying color values at the coarse pixel rate. By removing the upsampling stage, CPS can improve the overall performance.
Position Only Shading Tile Based Rendering (PTBR)
The motivation of tile-based rendering is to reduce memory bandwidth by efficiently managing multiple render passes to data per tile on die.
In order to support tile based rendering, Gen11 adds a parallel geometry pipeline that acts as a tile binning engine. It is used ahead of the render pipeline for visibility binning prepass per tile. It loops over geometry per tile and consumes visibility stream for that tile.
PTBR accomplishes its goal to keep data per tile on die by utilizing the L3 cache which has been enhanced to support color and Z formats. This collapses all the memory reads and writes within the L3 cache thereby reducing the external bandwidth.
3 SYSTEM ON A CHIP (SOC) ARCHITECTURE
Intel’ processors are complex SoCs integrating multiple CPU cores, Intel® Gen11 processor graphics and additional fixed functions all on a single shared silicon die. The architecture implements multiple unique clock domains, which have been partitioned as a per-CPU core clock domain, a processor graphics clock domain, and a ring interconnect clock domain. The SoC architecture is designed to be extensible for a range of products and enable efficient wire routing between components within the SoC.
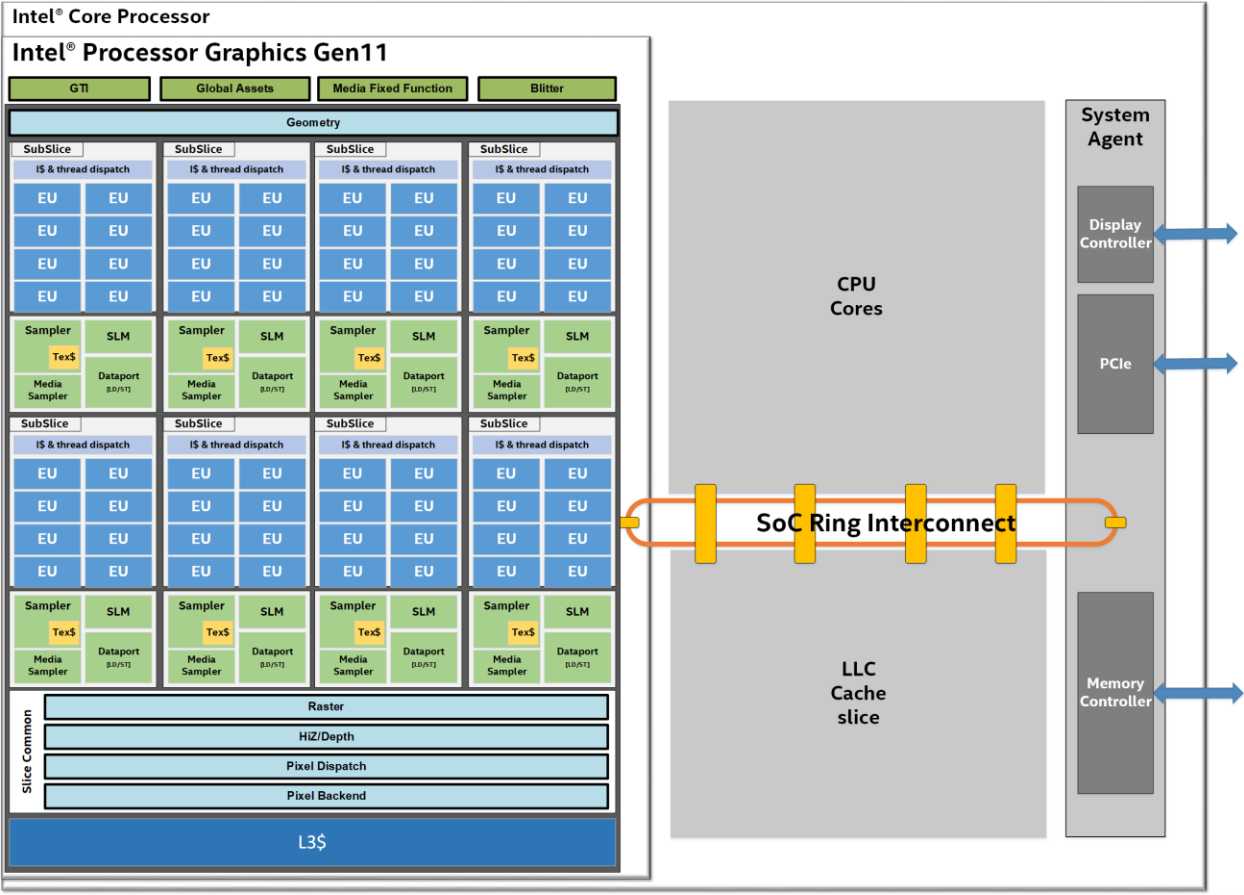
Intel® core processor, SoC and its ring interconnect architecture.
3.1 RING INTERCONNECT
The on-die bus between CPU cores, caches, and Intel® processor graphics is a ring based topology with dedicated local interfaces for each connected “agent” including the Intel processor graphics. A system agent is also connected to the ring which facilitates all off-chip system memory transactions to/from CPU cores and to/from Intel processor graphics. Intel® processors include a shared Last Level Cache (LLC) that is also connected to the ring. In addition, the LLC is also shared with Intel processor graphics.
4 THE GEN11 PROCESSOR GRAPHICS ARCHITECTURE
Gen11 architecture is an evolution over Gen9 with enhancements throughout the architecture to improve performance per flop by removing bottlenecks and improving the efficiency of the pipeline.
Gen11 is a 64EU Architecture supporting 3D rendering, compute, programmable and fixed function media capabilities. Gen11 architecture is split into: Global Assets which contains some fixed function blocks that interface to the rest of the SoC, the Media FF, the 2D Blitter and the Slice. The Slice houses the 3D Fixed Function Geometry, 8 sub-slices containing the EUs, and a slice common that contains the rest of the fixed function blocks supporting the render pipeline and L3 cache. Figure2 reflects this categorization.
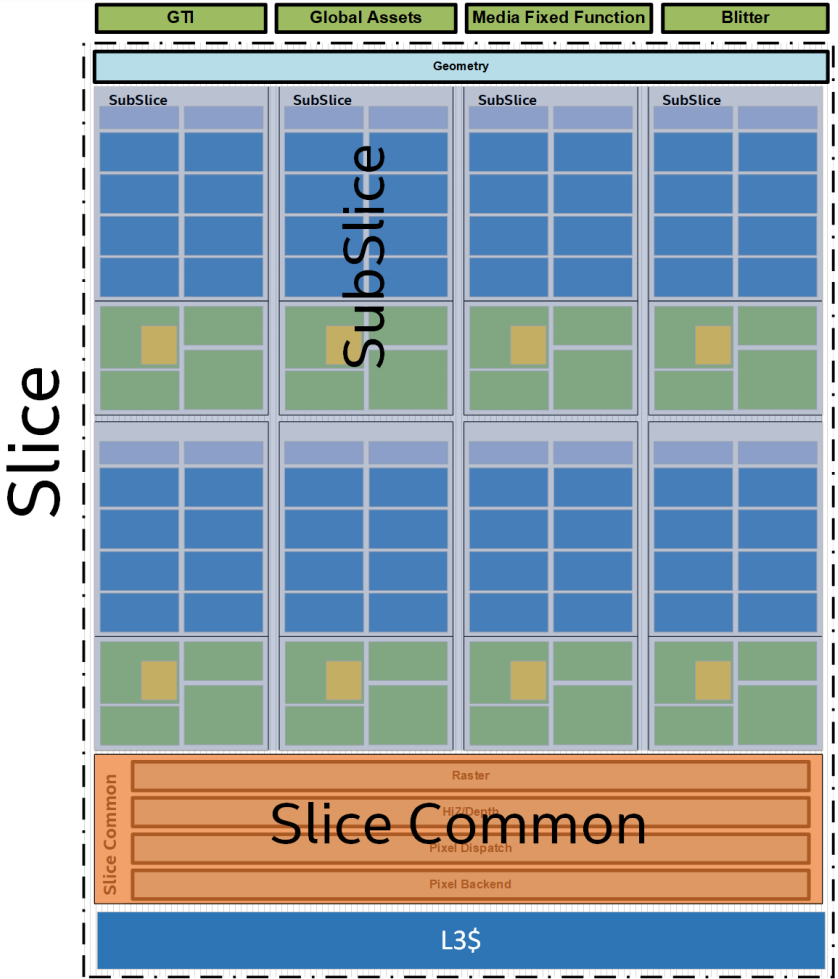
Gen11 Slice Architecture
4.1 GLOBAL ASSETS, MEDIA FF AND GTI
Global Assets presents a hardware and software interface from GPU to the rest of the SoC including Power Management.
Graphics Technology Interface (GTI) is the gateway between GPU and the rest of the SoC. The rest of the SoC includes memory hierarchy elements such as the shared LLC memory and system DRAM.
The GTI in Gen11 has been improved to provide higher bandwidth, going from 32B/clock to a 64B/clock interface for write operations. Additionally, the internal queues are sized to handle latency and higher bandwidth in the SoC.
As shown in Figure 2, Media Fixed Functions (Media FF) are located outside of the Slice and the Media Sampler is placed alongside the Texture Sampler inside the slice. The Media Sampler is a co-processor to the EU to execute select media primitives while the Media FF’s perform larger tasks (e.g. frame or slice boundary) with independent front-ends including the Multi-format Codec (MFX), Visual Quality Enhancement (VQE) and Scaler and Format Conversion (SFC) units. MFX performs decode and encode of various video codec standards, VQE is a pixel processing pipeline for prepost-processing, and SFC is an in-line scaler with memory format conversion capabilities.
The Media FF baseline configuration increases in Gen11 to include 2 MFX (up from 1 in Gen9) along with 1 VQE and 1 SFC. The 2 MFX units can be used for better concurrency such as video playback and video encoding simultaneously. Alternatively, workloads can utilize both engines concurrently to increase performance or reduce clock frequencies to increase battery life.
With Gen11, MFX VP9 decode bit depth support is increased up to10bits which is required for HDR video scenarios. Additionally, both HEVC and VP9 have been improved to support higher quality chroma subsampling of 4:2:2 and 4:4:4 for both HEVC and VP9. 4:2:2 benefits users in high-end video production while 4:4:4 is optimal for screen content such as textdocument screen recording and sharing. MFX encoding on Gen11 introduces VP9 support and significantly improves HEVC encoding compression efficiency over Gen9.
Gen11 VQE expands hardware denoise bit depth to 10bits. High dynamic range (HDR) workloads will benefit from new software programmable 3DLUT tables such has HDR2HDR and HDR2SDR tone mapping.
4.2 ARCHITECTURE CONFIGURATIONS, SPEEDS, AND FEEDS
The following table presents the theoretical peak throughput of the compute architecture of Intel processor graphics, aggregated across the entire graphics product architecture. Values are stated as “per clock cycle”, as final product clock rates were not available at time of this writing. It also shows a comparison to Gen9 GT2
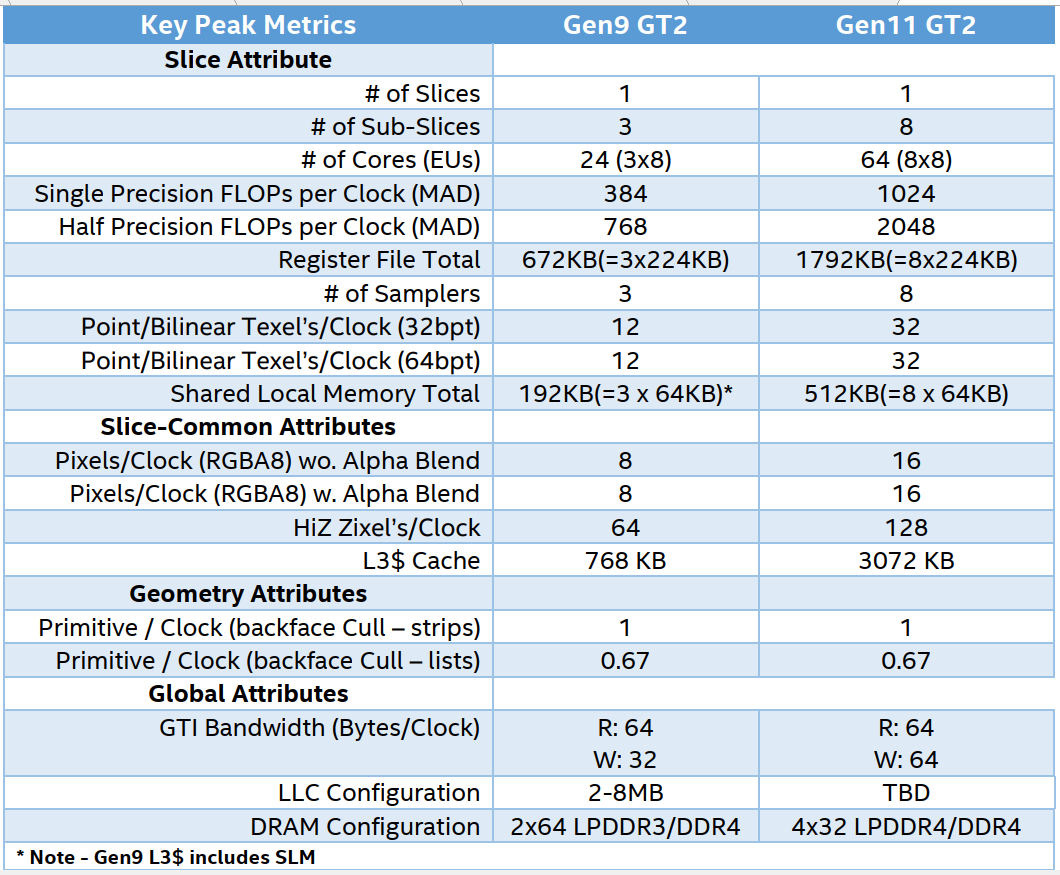
Figure 3: Key Peak Metrics Gen9 and Gen11
4.3 SLICE ARCHITECTURE
For Gen11-based products, 8 Subslices are aggregated into 1 slice. Thus a single slice aggregates a total of 64 EU. Aside from grouping Subslices, the Slice integrates additional logic for the geometry, L3 cache, and the Slice Common

Gen11 detailed block diagram.
4.3.1 Geometry
Gen11 3D Geometry Fixed Function contains the typical render front-end that maps to the logical pipeline in DirectX™, Vulkan™, OpenGL™ or Metal™ APIs. Additionally, it includes a Position Only Shading pipeline, or POSh pipeline used to implement Tile-Based Rendering (PTBR). This Section describes the traditional geometry pipeline while section 5.2 describes the POSh pipeline used in tile based rendering.
Vertex fetch (VF), one of the initial stages in the geometry pipe is responsible for fetching vertex data from memory for use in subsequent vertices, reformatting it, and writing the results into an internal buffer. Typically, a vertex consists of more than one attribute, e.g. position, color, normal, texture coordinates, etc. Usage of more vertex attributes has grown with increases in workload complexity. To that end, Gen11 increases the VF input rate from 4 attributes/clock to 6 attributes/clock as well as improves the input data cache efficiency. Another important VF change in Gen11 is the increase in number of draw calls handled concurrently to enable streaming of back to back draw calls. Newer APIs like DX12™* and Vulkan™* have significantly reduced the overheads for draw calls, enabling workloads to improve visuals by increasing the number of draw calls per frame.
Gen11 has also made tessellation improvements. It provides up to a 2X increase in the Hull Shader thread dispatch rate as well as further increases the output topology efficiency, especially for patch primitives subject to low tessellation factors.
4.3.2 Subslice Architecture
In Gen11 architecture, arrays of EUs are instantiated into a group called a Subslice. For scalability, product architects can choose the number of EUs per subslice. For most Gen11- based products, each subslice contains 8 EUs. Each subslice contains its own local thread dispatcher unit and its own supporting instruction caches. Each Subslice also includes a 3D texture sampler unit, a Media Sampler Unit and a dataport unit.
4.3.2.1 Execution Unit (EU) Architecture
The foundational building block of Gen11 architecture is the execution unit, commonly abbreviated as EU. The architecture of an EU is a combination of simultaneous multi-threading (SMT) and fine-grained interleaved multi-threading (IMT). These EUs are compute processors that drive multiple issue, single instruction, multiple data arithmetic logic units (SIMD ALUs) pipelined across multiple threads, for high-throughput floating-point and integer compute. The fine-grain threaded nature of the EUs ensures continuous streams of ready to execute instructions, while also enabling latency hiding of longer operations such as memory scatter/gather, sampler requests, or other system communication. Depending on the software workload, the hardware threads within an EU may all be executing the same compute kernel code, or each EU thread could be executing code from a completely different compute kernel.
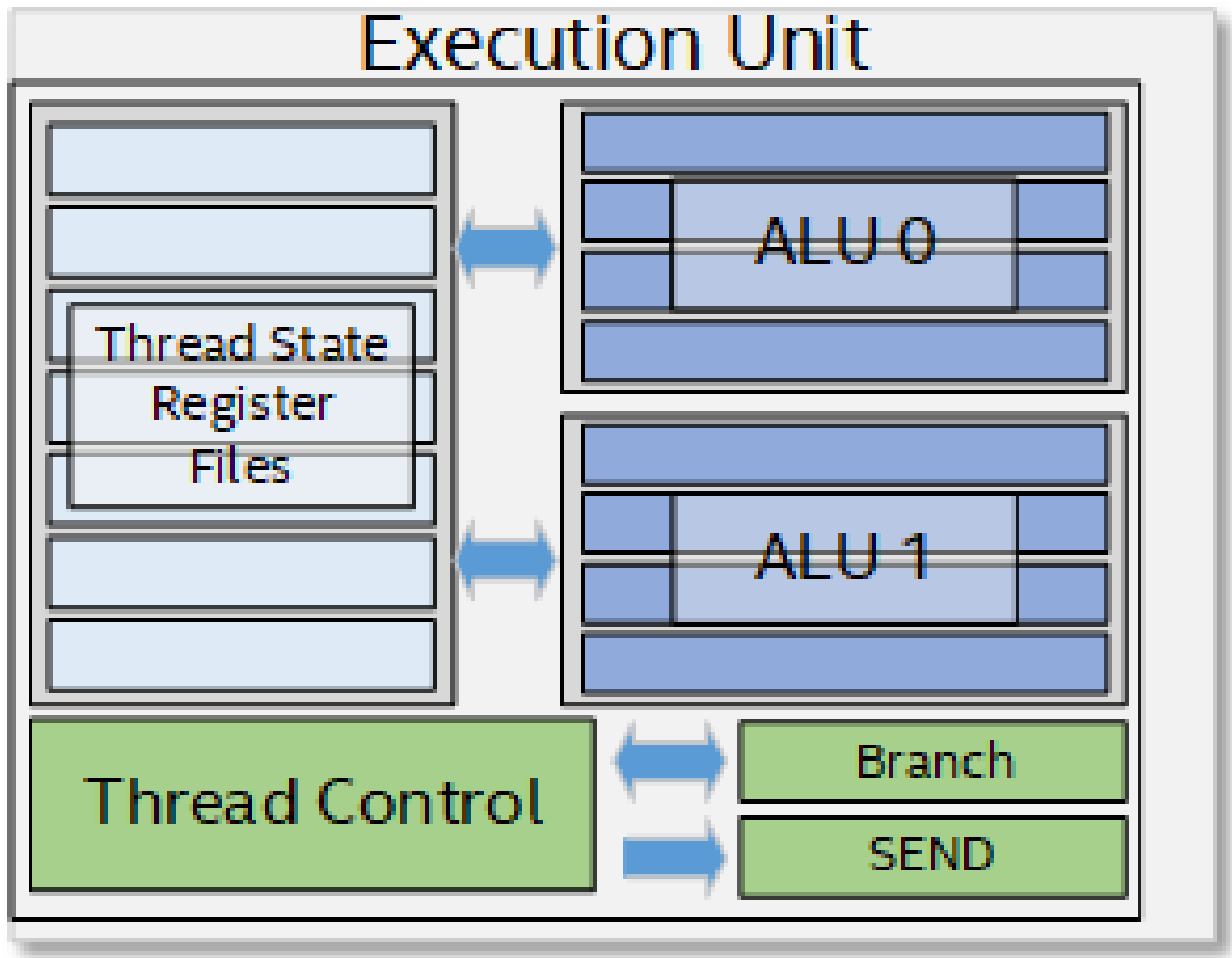
The Execution Unit (EU)
4.3.2.2 SIMD ALUs
In each EU, the primary computation units are a pair of SIMD floating-point units (ALUs). Although called ALUs, they support both floating-point and integer computation. These units can execute up to four 32-bit floating-point (or integer) operations, or up to eight 16-bit floating-point operations. Effectively, each EU can execute 16 FP32 floating point operations per clock [2 ALUs x SIMD-4 x 2 Ops (Add + Mul)] and 32 FP16 floating point operations per clock [2 ALUs x SIMD-8 x 2 Ops (Add + Mul)].
Each EU is multi-threaded to enable latency hiding for long sampler or memory operations. Associated with each EU is 28KB register file (GRF) with 32bytes/register.
As depicted in Figure 4, one of the ALUs support 16-bit and 32-bit integer operations and the other ALUs provides extended math capability to support high-throughput transcendental math functions.
4.3.2.3 SIMD Code Generation for SPMD Programming Models
Compilers for single program multiple data (SPMD) programming models, such as OpenCL™*, Microsoft DirectX** Compute Shader, OpenGL** Compute, and C++AMP™*, generate SIMD code to map multiple kernel instances2 to be executed simultaneously within a given hardware thread. The exact number of kernel instances per-thread is a heuristic driven compiler choice. We refer to this compiler choice as the dominant SIMD-width of the kernel. In OpenCL™* and DirectX™* Compute Shader, SIMD-8, SIMD-16, and SIMD-32 are the most common SIMD-width targets.
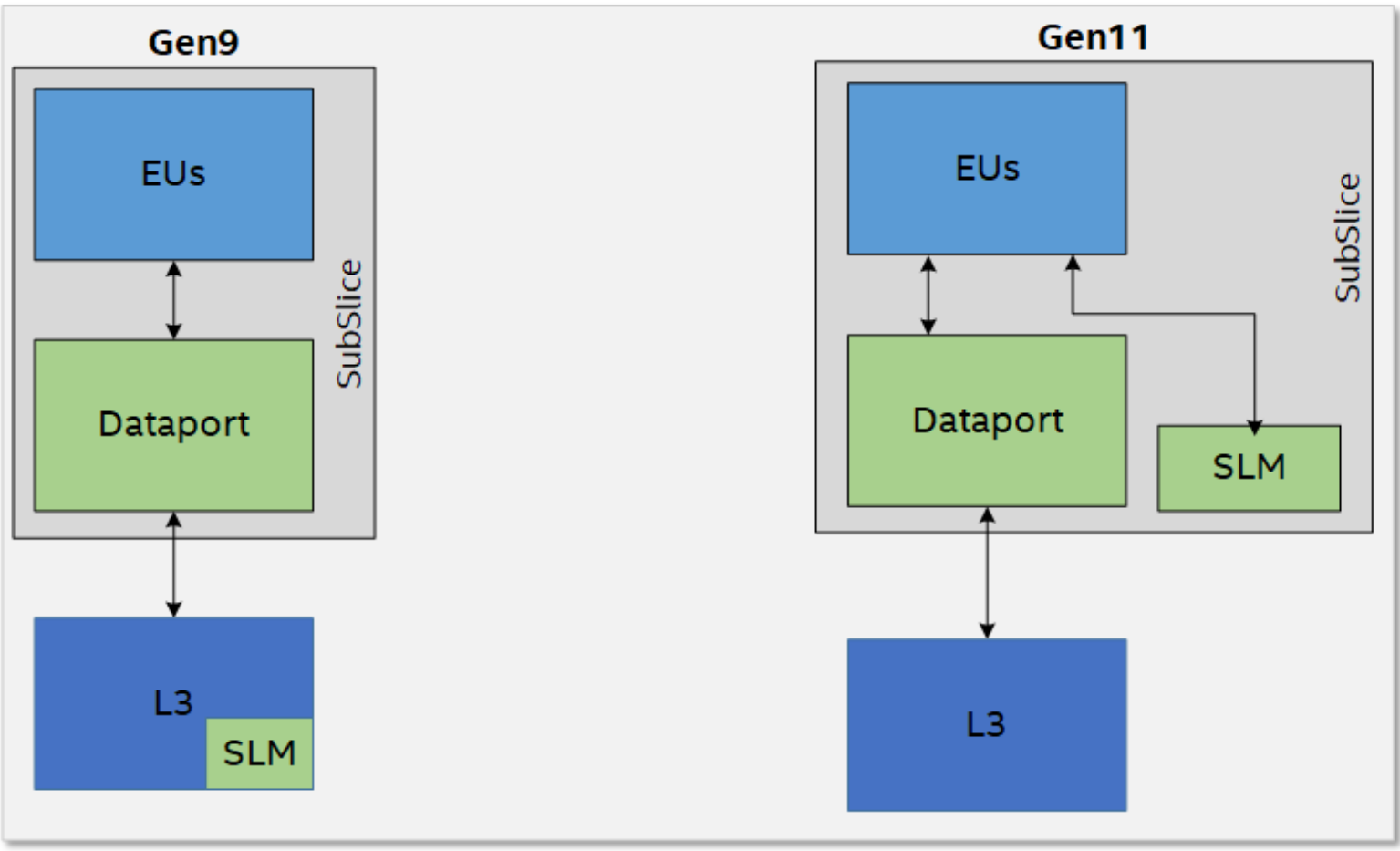
4.3.3 Shared Local Memory
The SLM is a 64KB highly banked data structure accessible from the 8 EUs in the Subslice. The change in architecture is depicted Figure 5. In Gen11 architecture, the SLM and memory access are split such that the one is through the dataport function while the other is accessed directly from the EUs.
The proximity to the EUs provides low latency and higher efficiency since SLM traffic does not interfere with L3/memory access through the dataport or sampler. The SLM is banked to byte granularity allowing high degree of access flexibility from the EUs. This change provides an increase in the overall effective rate of local and global atomics.
SPMD programming model constructs such as OpenCL’s™* local memory space or DirectX™* Compute Shader’s shared memory space are shared across a single work-group (threadgroup). For software kernel instances that use shared local memory, driver runtimes typically map all instances within a given OpenCL™* work-group (or a DirectX™* thread group) to EU threads within a single subslice. Thus all kernel instances within a work-group will share access to the same 64 Kbyte shared local memory partition. Because of this property, an application’s accesses to shared local memory should scale with the number of subslices.
EU latency and atomic efficiency
4.3.4 Texture Sampler
The Texture Sampler is a read-only memory fetch unit that may be used for sampling of texture and image surface types 1D, 2D, 3D, cube, and buffers. The sampler includes a cache, a decompressor, and a filter block. The Texture Sampler supports dynamic decompression of many block compression texture formats such as DirectX™* BC1-BC7, and OpenGL™* ETC, ETC2, and EAC. Additionally, the texture sampler supports lossless compressed surfaces. The sampler is also compliant with the latest Compute and 3D API’s for capability and quality.
Improvements on Gen11 include:
Sampling rate for anisotropic filtering of 32bit surface formats is increased by 2X for all depths of anisotropy (2X anisotropic filtering is now the same rate as trilinear filtering).
Sampling rate on volumetric surfaces has been increased by 2X on point sampled 32bit formats as well as bilinear filtered 64bit formats (point-sample is now full-rate of 4ppc for most surface formats).
Sampling rate for trilinear filtering of 2D surfaces with 64bit surface formats is increased by 2X.
4.3.5 Dataport
Each Subslice also contains a memory interface unit called the Dataport. The Dataport supports efficient un-typed/typed read/write operations to L3 cache, render cache and other buffers through flexible SIMD scatter/gather operations. To maximize memory bandwidth, the unit dynamically coalesces scattered memory operations into fewer operations over nonduplicated 64-byte cache line requests. For example, a SIMD-16 gather operation against 16 unique offset addresses for 16 32-bit floating-point values, might be coalesced to a single 64- byte read operation if all the addresses fall within a single cache line.
Gen11 reduces L3 cache and memory BW for blend operations that do not require read access to target surfaces.
4.4 SLICE COMMON
4.4.1 Raster
The Raster block converts polygons to a block of pixels called subspans. Gen11 significantly increases the conversion rate by 16x for 1xAA and by 4X for 4xMSAA.
In addition to normal rasterization, Gen9 supports conservative rasterization which tests pixel for partial coverage and marks it as covered for rasterization. This implementation meets the requirements of tier3 hardware per D3D12 specification and enables advanced rendering algorithms for collision detection, occlusion culling, shadows or visibility detection. Gen11 improves conservative rasterization throughput by about 8x.
Besides supporting rendering primitives, Gen devices also support line rendering which are typically important in workstation applications.
4.4.2 Depth
The depth test function is used to perform the “Z Buffer” hidden surface removal. The depth test function can be used to discard pixels based on a comparison between the incoming pixee
l’s depth value and the current depth buffer value associated with the pixel
Depth tests are performed at two levels of granularity, coarse and fine. The coarse tests are performed by HiZ where testing is done on 8x4 pixel block granularity. In addition, the HiZ block supports Fast Clear which allows clearing depth without writing the depth buffer. The test performed at a finer granularity (per pixel, per sample) are done by the Z block.
In Gen11, the Z buffer min/max is back annotated into HiZ buffer reducing future nondeterministic or ambiguous tests. When HiZ buffer does not have visibility data till post shader, the resulting tests are nondeterministic in HiZ resulting in Z to per pixel testing. Back annotation allows updating the HiZ buffer with results from Z buffer as shown in figure 6. HiZ test range is narrowed, resulting in coarse testing instead of pixel level for normal rendering or per sample level when MSAA is enabled. Thus, the overall depth test throughput is increased while the corresponding Z memory BW is simultaneously decreased.
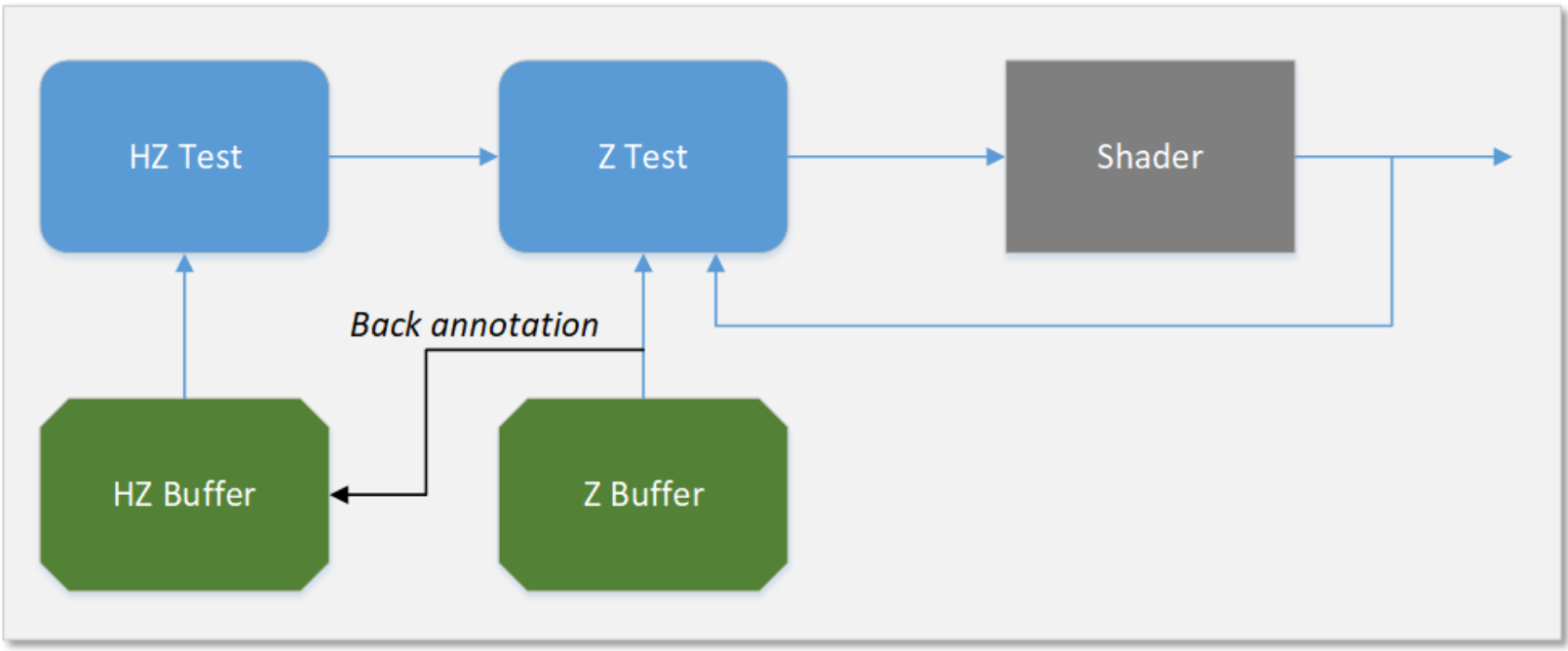
Back annotation depth test
4.4.3 Pixel Dispatch
The Pixel Dispatch block accumulates subspans/pixel information and dispatches threads to the execution units. The pixel dispatcher, decides the SIMD width of the thread to be executed, choosing between SIMD8, SIMD16 and SIMD32. Pixel Dispatch chooses this to maximize execution efficiency and utilization of the register file. The block load balances across the shader units and ensures order in which pixels retire from the shader units.
In Gen11, pixel dispatch includes the function of “coarse pixel shader” which is described in detail in Sections 5.1. When CPS is enabled, the coarse pixels generated are packed whichh
reduces the number of pixel shading invocations. The reference or the mapping of a coarse pixel to pixel is maintained until the pixel shader is executed.
4.4.4 Pixel Backend/Blend
The Pixel Backend (PBE) is the last stage of the rendering pipeline which includes the cache to hold the color values. This pipeline stage also handles the color blend functions across several source and destination surface formats. Lossless color compression is handled here as well.
Gen11 exploits use of lower precision in render target formats to reduce power for blending operations
4.4.5 Level-3 Data Cache
In Gen11, the L3 data cache capacity has been increased to 3MB. Each application context has flexibility as to how much of the L3 memory structure is allocated in:
Application L3 data cache
System buffers for fixed-function pipelines.
For example, 3D rendering contexts often allocate more L3 as system buffers to support their fixed-function pipelines.
All sampler caches and instruction caches are backed by L3 cache. The interface between each Dataport and the L3 data cache enables both read and write of 64 bytes per cycle.
Z, HiZ, Stencil and color buffers may also be backed in L3 specifically when tiling is enabled.
In typical 3D/Compute workloads, partial access is common and occurs in batches and makes ineffective use of memory bandwidth. In Gen11, when accessing memory, L3 cache opportunistically combines partial access of a pair of 32B to a single 64B thereby improving efficiency.
4.5 MEMORY
4.5.1 Memory Efficiency Improvements
Intel® processor graphics architecture continuously invests in technologies which improve graphic memory efficiency besides improving raw unified memory bandwidth.
Gen9 architecture introduced lossless compression of both render targets and dynamic textures. Games tend to have a lot of render to texture cases where the intermediate rendered buffer is used as a texture in subsequent drawcalls within a frame. As games target higher quality visuals, the bandwidth used by dynamic textures as well as higher resolution becomes increasingly important. Lossless compression aims to mitigate this by taking advantage of the fact that adjacent pixel blocks within a render target vary slowly or are similar which exposes opportunity for compression. Compression yields write bandwidth savings when the data is evicted from L3 cache to memory as well as for read bandwidth savings in case of dynamic textures or alpha blending of surfaces. These improvements results in additional power savings.
Gen11 enables two new optimizations to lossless color compression:
Support for sRGB surface formats for dynamic textures. Use of gamma corrected color space is important especially as the usage of high dynamic range is increasing
The compression algorithm exploits the property that a group of pixels can have the same color when shaded using coarse pixel shading as discussed in section 5.1.
Additionally, memory efficiency is further improved by tile based rendering technology (PTBR) discussed in section 5.2. Fundamentally, it makes the render target and depth buffer stay on chip memory during the render pass while overdraws are collapsed. There are opportunities to discard temporary surfaces by not writing back to memory. PTBR additionally improves sampler access locality and makes on chip cache hierarchy more efficient.
4.5.2 Unified Memory Architecture
Intel® processor graphics architecture has long pioneered sharing DRAM physical memory with the CPU. This unified memory architecture offers a number of system design, power efficiency, and programmability advantages over PCI Express-hosted discrete memory systems.
The obvious advantage is that shared physical memory enables zero copy buffer transfers between CPUs and Gen11 compute architecture. By zero copy, we mean that no buffer copy is necessary since the physical memory is shared. Moreover, the architecture further augments the performance of such memory sharing with a shared LLC cache. The net effect of this architecture benefits performance, conserves memory footprint, and indirectly conserves system power not spent needlessly copying data. Shared physical memory and zero copy buffer transfers are programmable through the buffer allocation mechanisms in APIs such as Vulkan™*, OpenCL2™* and DirectX12™*.
Gen11 supports LPDDR4 memory technology capable of delivering much higher bandwidth than previous generations. The entire memory sub-system is optimized for low latency and high bandwidth. Gen11 memory sub-system features several optimizations including fabric routing policies, and enhanced memory controller scheduling algorithms which increases overall memory bandwidth efficiency. The memory sub-system also includes QOS features that help balance bandwidth demands from multiple high-bandwidth agents. Figure 7 shows the SoC chip and memory hierarchy.
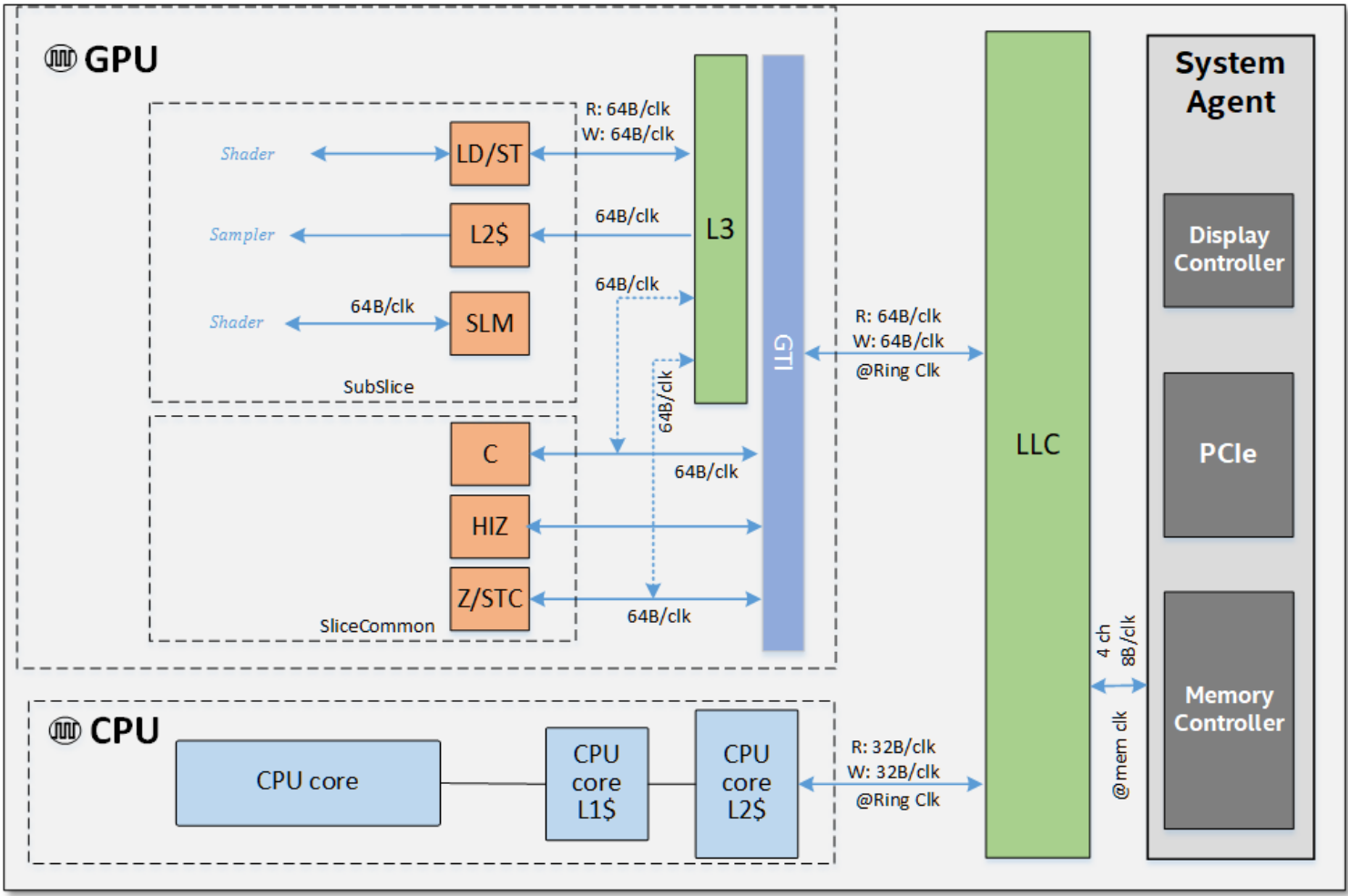
SoC chip level memory hierarchy and its theoretical peak bandwidths
4.6 DISPLAY CONTROLLER
The graphics story is not complete without describing the display controller which “paints” the images on the screen. Like Gen 9, the display controller in Gen11 is also integrated in the system agent largely because of the display’s affinity with memory. Over the life of a device, the display controller can consume far more memory bandwidth that any other client. This means that display controller is also one of the most active participants in power management of the SoC. Gen11 display controller has several new features which focus specifically on power management.
Panel Self Refresh and Display Context Save and Restore are two of the most prominent features. Panel Self Refresh is an embedded panel feature available on eDP™*. PSR panels have a memory copy of the most recently displayed frame which, when the display controller indicates, can be swapped for the display stream. This allows the display controller to stop clocks and go to a low power state. When combined with the Display Controller Save and Restore feature, it can save significant power by additionally shutting off power to the display pipelines. Display Save and Restore saves the context of the display controller into a sustain power SRAM, and then restores the state after the power returns. This feature not only savespower in the display controller, but also in the entire device as it allows the SoC to reach very deep power states while it is running.
Another key feature of Gen11 platform is the integration of the USB Type-C subsystem. The display controller has dedicated outputs for USB Type-C and DisplayPort™* alt mode is supported on all USB Type-C outputs. Additionally, output of the display controller can target the Thunderbolt controller, which can also tunnel DisplayPort™*.
The display controller also has made internal structural changes to improve performance. Chief among these is a shift to a wider pixel processing path in response to the increasing resolutions of monitors. As the number of pixels increases the rate at which the display controller must process them increases as well, so processing pixels two at time reduces the internal frequency required for the display controller by 50%. Even though this creates a larger display controller, it still comes out ahead as power is more directly impacted by frequency.
Another power feature is display streaming “race to halt”. This feature adds a large buffer on die for the display controller to fetch in to. This allows the display controller to collect pixels very quickly for a large part of the screen, and then shut down the fabric and memory controller while just using the streaming buffer. With the large buffer included in Gen11, the display engine can concentrate its memory accesses into a burst which allows the memory controller to go into power saving modes for longer periods of time than previous designs.
The display controller also supports a compressed memory format generated by the graphics engine to reduce memory bandwidth.
Display upgrades were not limited to power features. The display scaler, which is used for both plane scaling and pipe scaling also got an upgrade going from 7x5 tap filters to 7x7 filters which provides a notable increase in quality. The entire display pixel pipe has gained precision in response to the forthcoming deep color and High Dynamic Range displays. Deep Color refers to those displays that support a color gamut that is larger (sometimes much larger) than the standard sRGB color space. High Dynamic Range device additionally increase the range of brightness levels available.
Finally, support for DisplayPort™* Adaptive Sync has been added for the embedded display. This feature allows the display in combination with a supported monitor to adjust the refresh rate based on the workload. This is usually used to adjust the refresh rate to match the frame rate of the renderer or media stream. This provides a significantly improved user experience over devices that do not support adaptive sync. Note, asynchronous mode typically referred to as Vsync off.
5.1 COARSE PIXEL SHADING

The canonical Citadel 1 CPS image rendered at 2560x1440 with a 1x1 pixel rate on the left and 2x2 CPS shading on the right. While CPS halves the number of shader invocations, there is almost no perceivable difference on a high pixel density display. An up-scaled image with no anti-aliasing applied is also shown for comparison rendered at 1280x720. Reprinted with permission from [Vaidyanathan et al. 2014].

Figure 10: In this image, the geometry with red boxes are identified as being sufficiently far away from the camera, and of minor significance to the overall image quality, so the color shading frequency can be reduced with no discernable impact to the visual quality on a per frame basis and improved overall frame rate over time.
Using Coarse Pixel Shading
Coarse Pixel Shading is easy to integrate into an application and requires no re-authoring or re-export of the content in the application. After initialization of CPS and enabling via the pipeline state description the CPS rate only needs to be specified before a draw call is executed. In addition, we support a foveated scheme described in more detail in the Coarse Pixel Shading Whitepaper available at the Intel Developer Zone [Lake, et al. 2019].
Integrating CPS into an application
Coarse Pixel Shading is a key feature and the best way to take advantage of it is leveraging the integration of the use cases described above into your application. For integration details and sample code see the CPS programming guide available on the Intel Developer Zone.
CPS and MSAA
Coarse Pixel shading and MSAA work together but remain decoupled in Gen11. For example, 4xMSAA with 2x2 coarse pixels means that there are 4 samples within a single regular pixel with 4 regularly sized pixels making up the single coarse pixel. Each pixel continues to have 4 sample points for coverage but will obtain the color value for the coarse pixel from the center (or centroid) of the coarse pixel.
5.2 POSITION ONLY SHADING TILE BASED RENDERING
Tile-based rendering technology has been employed to reduce the enormous bandwidth demands of contemporary GPUs. In a tile-based approach, a render target is divided into n number of rectangular regions – i.e. tiles – that in turn are rendered one at a time. At the most basic level, only the triangles that affect a tile are rendered to limit the working set.
One can assume that these tile-based rendering engines move the color and depth buffer out of main memory to the on-chip tile cache. Since this cache is much closer to the compute engines, far less power is required to access it. The bandwidth advantage comes by implementing the depth/stencil testing and blending entirely via on-chip tile cache.
Moreover, tiling also helps in suppressing the write bandwidth associated with overdrawn pixels. Finally, there are other advantages where the tiling engines have to write only a minimum set of results to memory – i.e. no depth/stencil values, and no multi-sample render target data.
Block diagram of Position only tile based rendering (PTBR)Block diagram of Position only tile based rendering (PTBR)
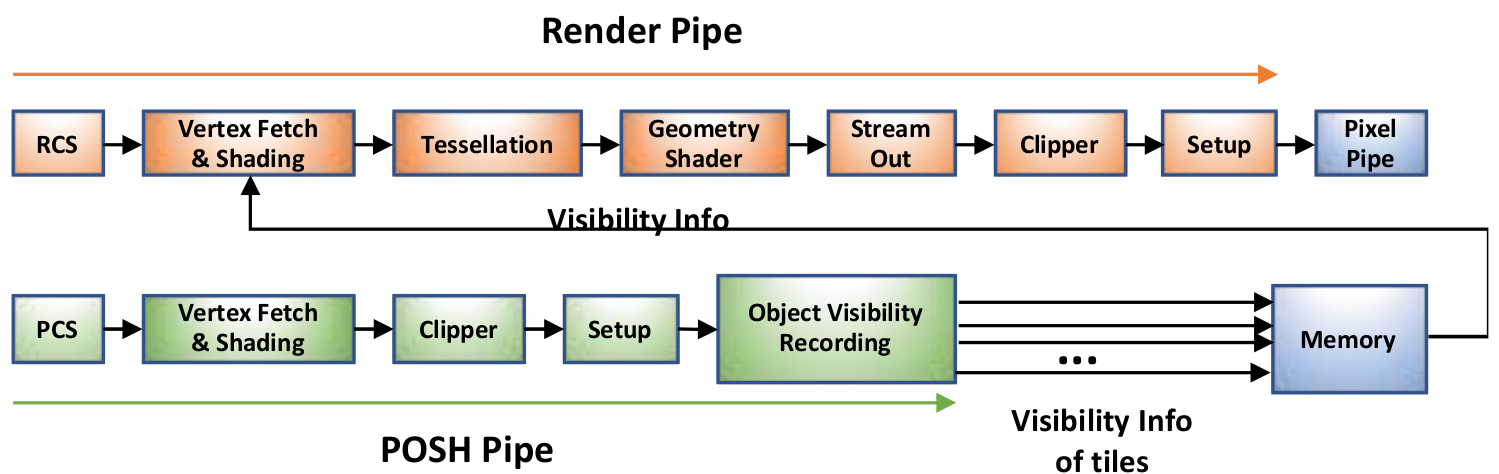
As depicted in Figure 11, Gen11 adopts position only shading tile-based rendering (PTBR). The PTBR paradigm includes the utilization of two distinct geometry pipes: a new position only shading (POSH) pipe and a typical render pipe.
The POSH pipe executes the position shader in parallel with the main application, but typically generates results much faster as it only shades position attributes and avoids rendering of pixels. The POSH pipe runs ahead and uses the shaded position attribute to compute visibility information for triangles to gauge whether they are culled or not. Object visibility recording unit of the POSH pipe calculates the visibility, compresses the information and records it in memory. Note that the object visibility recording unit can be programmed to record visibility of multiple tiles simultaneously.
The POSH pipe is programmed via the driver to get the visibility for multiple streams in parallel where each stream represents a tile of the whole render target. Next, the POSH pipe loops over geometry per tile and consumes per tile visibility for deciding whether the geometry is included or excluded which is then subsequently sent to the render pipe. The render pipe is responsible for rendering each of the tiles.
Additionally, the size and the number of tiles are calculated via the driver where it uses information like number of attached render targets and surface formats of the render-targets to generate additional information of bytes/pixel. Tile cache size and bytes/pixel determines the dimensions as well as the number of tiles.
Moreover, tile-based rendering assists Multisample Anti-Aliasing (MSAA) to resolve bandwidth performance. Furthermore, PTBR can also be used to support tiling extensions like discarding depth/multi-sample render-targets, pixel local storage etc. Note that PTBR does not require ISV intervention unlike CPS, however, PTBR can provide benefit to applications which utilize 3D graphics APIs designed for tile-based rendering architectures.
5.3 INTEL ADAPTIVE SYNC
Modern day personal computer usages can typically include gaming, video playback, browsing, and office usages such as PowerPoints™* and Spreadsheets™*. As a consequence, the various content is created at different frame rates. Traditionally, display panels function at a constant refresh rate (e.g.60Hz), which in most cases, doesn’t exactly match with the content frame rates that are unique and varying.
For example, the rendered frame rate for gaming could vary from 30 frames per second (fps) to 120 fps or more. The usual frame rates for video playback are 24 fps, 30 fps, and 60 fps while the frame rates for the other desktop applications might be much lower.
With the V-Sync mode of operation, the display buffer is only refreshed during the vertical blanking interval between frames. If the usage’s render framerate is lower than the refresh rate of the display, there will be repeat frames rendered on the display from time to time. This effect degrades the user experience by manifesting as stutter and lag. If the render framerate is higher than the refresh rate of the display, the updated frame must wait until the vertical blanking period to be displayed on the panel. Although this is technically undesirable, it may not be perceivable to the user.

Figure 12: Screen tearing example 1
Contemporary display controllers support a mode where the updated frame can immediately be delivered to the display without waiting for the vertical blanking period and hence avoiding the delay but creating artifacts known as “tearing.”. This mode is known as Asynchronous (Async) mode. In Async mode, screen tearing is apparent when the rendered frame rate is not in sync with the display panel refresh rate. Asynchronous mode typically referred to as Vsync off. The display controller tries to always read the latest updated frame from the GPU but keep the display refresh rate constant. During such an operation, when the display controller receives a new frame buffer when a partial write out of the current frame is done, it immediately switches to fetch the data from the new frame buffer for the remaining portion of the current display frame. This creates the unwanted and annoying tearing effect on the display. The following pictures show the screen tearing effect when the Display controller is running in Async mode.
Adaptive sync is a VESA™* DisplayPort™* (DP) standard whose function is to dynamically synchronize the display panel refresh rate with the varying GPU render rate. In Gen11, it provides stutter and tear free gaming possible on eDP™* panels that support the dynamically adjustable refresh rate range.
When the frame render rate by the GPU falls in the supported refresh rate range of the panel, the display controller adapts and syncs the display refresh rate to that of the GPU. Display controller makes this by increasing or decreasing the frame blanking period to either decrease or increase the display refresh rate respectively to match the GPU render rate. This totally alleviates the issue of the screen tear that would occur if the display controller runs on the Async mode of operation.
When the GPU render rate is lower than the minimum refresh rate supported by the panel, display controller's low frame rate compensation feature makes sure to fill in the additional frames to decrease visual artifacts. When the GPU render rate is higher than the maximum refresh rate, the frame refresh on the panel occurs at the maximum refresh rate of the panel.
Figure 13 shows an identical frame comparison of between Async and Adaptive Sync modes of operations respectively.
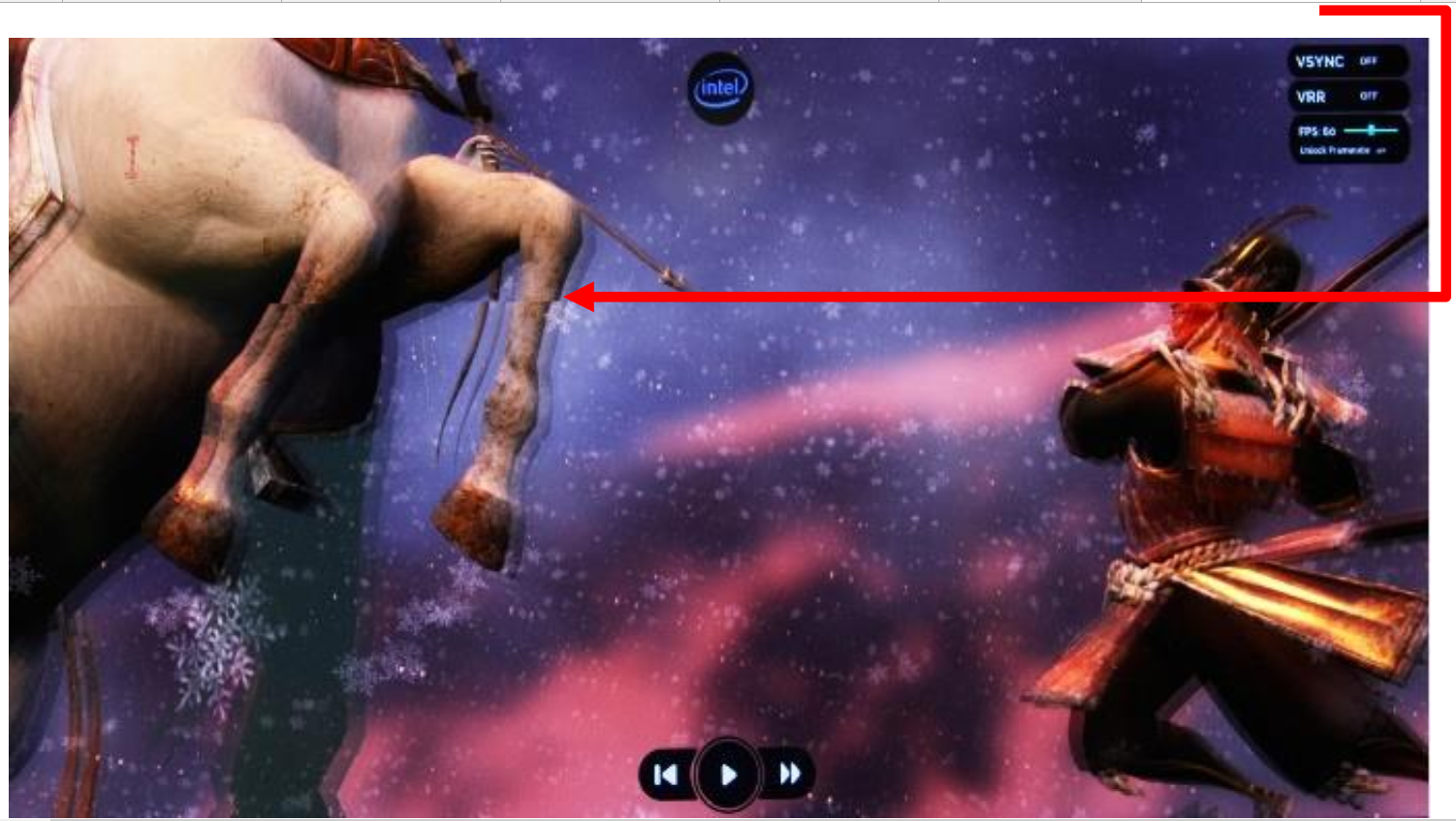

Figure 13: Adaptive sync solution for frame tearing