用于大尺度图片识别的非常深的卷积网络
使用一个带有非常小的(3*3)的卷积核的结构去加深深度,该论文的一个十分重要的改进就是它将卷机网络的深度增加到了16-19层,且可以用于比较大224*224的图片当中
其最大的特点就是采用了大量卷积核尺寸为3*3的卷积层,小尺寸的卷积核可以大大减少计算量。其网络层数从11层到19层不等,主要由卷积层、池化层和全连接层组成,这一点延续了AlexNet的特点。该网络最后几层采用的是全连接层,而且全连接层的输出节点很大(4096),这种设计虽然对提升模型效果有帮助,但是会带来大量的参数量,这也是后续一些做模型加速和压缩算法关注的点,最常见的做法就是使用其他网络层比如卷积层替代这些全连接层
1.配置说明
在训练中,网络的输入大小是固定的224*224图片,对图片做的唯一预处理操作是将训练集中图片每个像素减去他们的平均RGB值。使用了3*3大小的接受域(即卷积核),从下面的图中我们也可以看出也用网络C的配置中使用了1*1大小的接受域,可以看作是一个输入channels的线性转换(后面跟着非线性函数ReLU)。stride设置为1;对于3*3接受域padding设置为1;使用了5个max-pooling层,都跟在卷积层的后面,窗口设置为2*2,stride设置为2。之后还跟着3个全卷积层,前两个有4096个channels,最后一个的输出节点数是1000,因为ImageNet数据集的类别数是1000
只有网络A-LRN带有LRN(local response normalization)归一化方法,从下面可见其并没有改善性能,而且还增加内存消耗和计算时间
有A-E 6个不同深度的网络,从网络A的11层(8个卷积层和3个全连接层)到网络E的19层(16个卷积层和3个全连接层)。网络的宽度(即通道的数量)从第一层的64,在经过一个max-pooling层后增加一倍,直到到达512层
之前的网络在第一个卷积层都是使用比较大的卷积核,如11*11且stride=4或7*7带着stride=2,这个网络使用的是3*3且stride=1的。可见两个3*3卷积层(中间没有空间池化层)等价于一个5*5层,三个卷积层等价于一个7*7层。
那么使用三个3*3卷积层替换一个7*7卷积层的好处是:
- 使用一个ReLU函数替换了三个ReLU函数,使决策函数更具分辨力
- 减少了参数的数量:假设三层3*3卷积层的输入和输出都是C个通道数,其参数有3*(32C2)=27C2,7*7的卷积层的参数有72C2=49C2
在网络C中添加了1*1卷积层,在不影响卷积层的接受域的情况下增加决策函数的非线性,并没有改变输入输出的channels的数量

2.分类框架
1)训练
batch size设置为256,momentum设置为0.9。正则化将weight decay(L2 penalty multiplier)设置为5*10-4,对于前两个全连接层的dropout正则化方法设置dropout ratio为0.5。学习率初始设置为10-2,并且当验证集的准确率停止上升时,lr = lr/10。总之学习率衰减了3次,学习停止在了74 epochs。所以我们推测尽管我们的网络对比2012的网络有着更多的参数和更大的深度,由于(a)更大的深度和更小的卷积核大小和(b)某一层的预初始化带来的隐含正则化效果,我们的网络只需要很少的epoch去收敛
网络权重的初始化是十分重要的,由于深度网络中梯度的不稳定性,初始化不佳会使学习陷入停滞。
为了规避这个问题,当我们训练的是如网络A这种比较浅的网络时使用的是随机初始化。然后,当训练更深层次的架构时,我们与net A一起初始化前四个卷积层和最后三个全连接层(中间的层都随机初始化)。对于预初始化的层我们不减少他们的学习率,而是在学习的过程中允许他们改变。对于随机初始化,我们是从均值为0方差为10-2的正态分布对权重进行采样的。偏置bias设置为0.
为了获得固定大小224*224的输入图片,对重置大小的训练图片进行随机剪切。为了让增加训练集,随机剪切后还进行了随机水平翻转和随机RGB颜色变换
训练图片大小的设置:
S:isotropically-rescaled训练图片的最小边,称其为训练尺度
当crop size被固定为224*224时,理论上S可以设置为任何不小于224的值。当S=224时,说明crop时剪切的是整个图片的数据;当S远远大于224时,crop将对应于图像的一小部分,包括一个小对象或一个对象部分。
考虑了两种设置训练尺度S的方法:
- 一种是固定S的大小,对应于单尺度训练(注意在采样裁剪中的图片内容仍能够代表多尺度图片数据)。在这个实验中设置了两个固定的S大小,即256和384。根据配置,我们一开始使用S=256进行训练,为了加速S=384的网络,将weight初始化为在S=256时预训练时得到的值,lr=10-3
- 另一个方法是设置S为多尺度,即每个图片重置大小的S的值随机在某个范围[Smin,Smax]取值(设置Smin=256,Smax=512)。 因为图片中的对象可能是不同的大小,在训练时将其作为考量是十分有效的。通过尺度抖动,该多尺度能够被看作是一种训练集增强方式,即单模型被训练去在一个大尺度范围中识别对象。因为速度的原因,我们通过微调有着同样配置,即预训练时有着固定的S=384的单尺度模型的所有层来训练多尺度模型,
2)测试
Q:预定义的图片重置大小的最小图片边,称为测试尺度
Q不需要等于训练尺度S,我们也会使用水平翻转来增加测试数据集
multi-crops
由于全卷积网络应用于整个图像,因此不需要在测试时对多个crops进行采样(Krizhevsky et al., 2012),效率较低,需要网络对每个crops重新计算。同时,像Szegedy等人(2014)所做的那样,使用大量的crops集可以提高精度,因为与全卷积网络相比,它可以对输入图像进行更精细的采样。
同时,multi-crop评价是dense评价的补充,由于不同的卷积边界条件:当应用一个ConvNet到一个crop中时,卷积特征映射将用0填充,然而在dense评估的情况下,对于相同crop,其填充自然来自于邻近的部分图像(由于卷积和空间池化),这大大增加了整体网络接受域,所以能够捕捉更多的上下文。虽然我们相信在实践中多crops的增加计算时间并不证明准确性的潜在收益,为了参考,我们使用每个尺度50个crops(5 × 5个规则网格,2次翻转)来评估我们的网络,总共是3种尺度以上的150个crops,相当于Szegedy et al. (2014)中4尺度以上的144个crops
3.结果
1)图片单尺度的评估-test

从结果可见A-LRN的效果并没有比A好,所以后面的B-E网络都没有使用BN层
我们也可以看见分类错误随着网络层次的增加分类的错误率在降低。可见在同一个深度的网络中C和D中,使用了1*1卷积核的C的性能差于使用了3*3的D。但是从C优于B我们又可以看出额外的非线性函数还是有用的,从D优于C可见使用并非微不足道的卷积核(即3*3的效果比1*1的好)能更好地获取空间内容
由上图可见(S在[256;512]两个值)的训练效果是优于(S=256或S=384)的。这证实了通过尺度抖动增强训练集确实有助于捕获多尺度图像统计量。
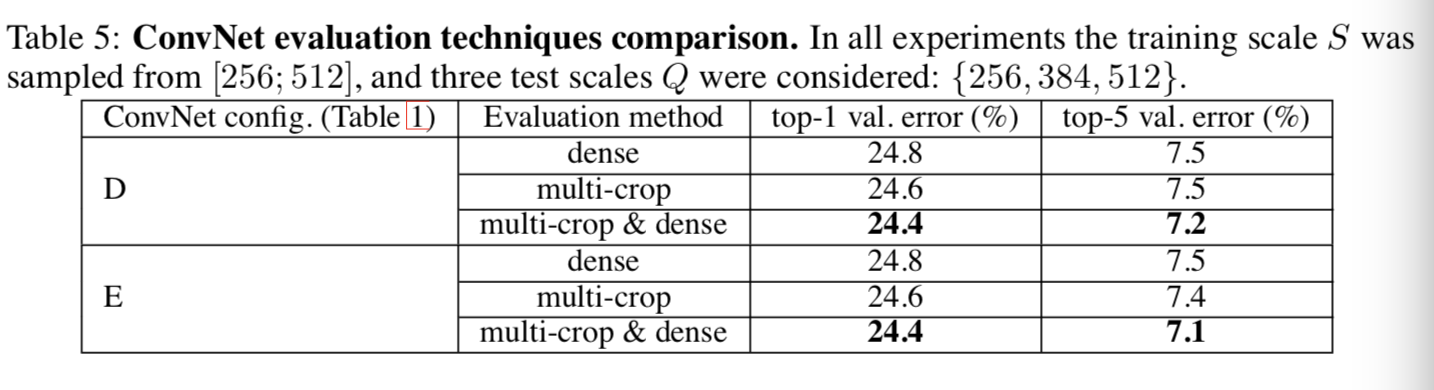
2)图片多尺度的评估-test
Q={S-32,S+32}。与此同时,在训练时使用了尺度抖动,即S在[256;512]两个值时,它将允许在测试时网络被应用在更宽的尺度范围中,Q={Smin, 0.5(Smin+Smax), Smax}
由下图可见在测试时的尺度抖动导致更好的性能
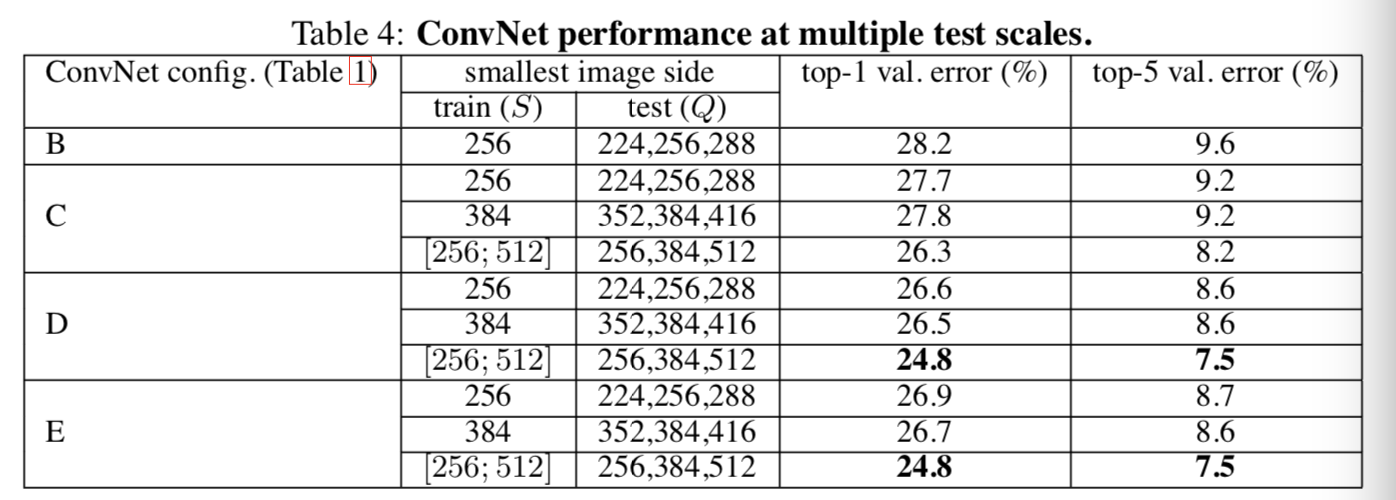
3)multi-crop评估
使用dense和multi-crop两种评估方法,还通过平均两者的softmax输出来评估两者的互补性。由下表可见multi-crop比dense的效果要好一些,且两者是互补的,因为他们两者结合的结果比他们各自的结果都要好