1,数据存储位置(Data location)概念
1.1 storage, memory, calldata, stack区分
在 Solidity 中,有两个地方可以存储变量 :存储(storage)以及内存(memory)。Storage变量是指永久存储在区块链中的变量。Memory 变量则是临时的,当外部函数对某合约调用完成时,内存型变量即被移除。
内存(memory)位置还包含2种类型的存储数据位置,一种是calldata,一种是栈(stack)。
(1) calldata
这是一块只读的,且不会永久存储的位置,用来存储函数参数。 外部函数的参数(非返回参数)的数据位置被强制指定为 calldata ,效果跟 memory 差不多。
(2) 栈(stack)
另外,EVM是一个基于栈的语言,栈实际是在内存(memory)的一个数据结构,每个栈元素占为256位,栈最大长度为1024。 值类型的局部变量是存储在栈上。
不同存储的消耗(gas消耗)是不一样的,说明如下:
- storage 会永久保存合约状态变量,开销最大;
- memory 仅保存临时变量,函数调用之后释放,开销很小;
- stack 保存很小的局部变量,免费使用,但有数量限制(16个变量);
- calldata的数据包含消息体的数据,其计算需要增加n*68的GAS费用;
storage 存储结构是在合约创建的时候就确定好了的,它取决于合约所声明状态变量。但是内容可以被(交易)调用改变。
Solidity 称这个为状态改变,这也是合约级变量称为状态变量的原因。也可以更好的理解为什么状态变量都是storage存储。
memory 只能用于函数内部,memory 声明用来告知EVM在运行时创建一块(固定大小)内存区域给变量使用。
storage 在区块链中是用key/value的形式存储,而memory则表现为字节数组
1.2 栈(stack)的延伸阅读
EVM是一个基于栈的虚拟机。这就意味着对于大多数操作都使用栈,而不是寄存器。基于栈的机器往往比较简单,且易于优化,但其缺点就是比起基于寄存器的机器所需要的opcode更多。
所以EVM有许多特有的操作,大多数都只在栈上使用。比如SWAP和DUP系列操作等,具体请参见EVM文档。现在我们试着编译如下合约:
pragma solidity ^0.4.13;
contract Something{
function foo(address a1, address a2, address a3, address a4, address a5, address a6){
address a7;
address a8;
address a9;
address a10;
address a11;
address a12;
address a13;
address a14;
address a15;
address a16;
address a17;
}
}
你将看到如下错误:
CompilerError: Stack too deep, try removing local variables.
这个错误是因为当栈深超过16时发生了溢出。官方的“解决方案”是建议开发者减少变量的使用,并使函数尽量小。当然还有其他几种变通方法,比如把变量封装到struct或数组中,或是采用关键字memory(不知道出于何种原因,无法用于普通变量)。既然如此,让我们试一试这个采用struct的解决方案:
pragma solidity ^0.4.13;
contract Something{
struct meh{
address x;
}
function foo(address a1, address a2, address a3, address a4, address a5, address a6){
address a7;
address a8;
address a9;
address a10;
address a11;
address a12;
address a13;
meh memory a14;
meh memory a15;
meh memory a16;
meh memory a17;
}
}
结果呢?
CompilerError: Stack too deep, try removing local variables.
我们明明采用了memory关键字,为什么还是有问题呢?关键在于,虽然这次我们没有在栈上存放17个256bit整数,但我们试图存放13个整数和4个256bit内存地址。
这当中包含一些Solidity本身的问题,但主要问题还是EVM无法对栈进行随机访问。据我所知,其他一些虚拟机往往采用以下两种方法之一来解决这个问题:
- 鼓励使用较小的栈深,但可以很方便地实现栈元素和内存或其他存储(比如.NET中的本地变量)的交换;
- 实现pick或类似的指令用于实现对栈元素的随机访问;
然而,在EVM中,栈是唯一免费的存放数据的区域,其他区域都需要支付gas。因此,这相当于鼓励尽量使用栈,因为其他区域都要收费。正因为如此,我们才会遇到上文所述的基本的语言实现问题。
2,不同数据类型的存储位置
Solidity 类型分为两类: 值类型(Value Type) 及 引用类型(Reference Types)。 Solidity 提供了几种基本类型,可以用来组合出复杂类型。
(1)值类型(Value Type)
是指 变量在赋值或传参时总是进行值拷贝,包含:
- 布尔类型(Booleans)
- 整型(Integers)
- 定长浮点型(Fixed Point Numbers)
- 定长字节数组(Fixed-size byte arrays)
- 有理数和整型常量(Rational and Integer Literals)
- 字符串常量(String literals)
- 十六进制常量(Hexadecimal literals)
- 枚举(Enums)
- 函数(Function Types)
- 地址(Address)
- 地址常量(Address Literals)
(2)引用类型(Reference Types)
是指赋值时我们可以值传递也可以引用即地址传递,包括:
- 不定长字节数组(bytes)
- 字符串(string)
- 数组(Array)
- 结构体(Struts)
引用类型是一个复杂类型,占用的空间通常超过256位, 拷贝时开销很大。
所有的复杂类型,即 数组 和 结构 类型,都有一个额外属性:“数据位置”,说明数据是保存在内存(memory ,数据不是永久存在)中还是存储(storage,永久存储在区块链中)中。 根据上下文不同,大多数时候数据有默认的位置,但也可以通过在类型名后增加关键字( storage )或 (memory) 进行修改。
变量默认存储位置:
- 函数参数(包含返回的参数)默认是memory;
- 局部变量(local variables)默认是storage;
- 状态变量(state variables)默认是storage;
局部变量:局部作用域(越过作用域即不可被访问,等待被回收)的变量,如函数内的变量。
状态变量:合约内声明的公共变量
数据位置指定非常重要,因为他们影响着赋值行为。
在memory和storage之间或与状态变量之间相互赋值,总是会创建一个完全独立的拷贝。
而将一个storage的状态变量,赋值给一个storage的局部变量,是通过引用传递。所以对于局部变量的修改,同时修改关联的状态变量。
另一方面,将一个memory的引用类型赋值给另一个memory的引用,不会创建拷贝(即:memory之间是引用传递)。
注意:
不能将memory赋值给局部变量。
对于值类型,总是会进行拷贝。
下面引用一段合约代码作说明:
pragma solidity ^0.4.0;
contract C {
uint[] x; // x 的数据存储位置是 storage
// memoryArray 的数据存储位置是 memory
function f(uint[] memoryArray) public {
x = memoryArray; // 将整个数组拷贝到 storage 中,可行
var y = x; // 分配一个指针(其中 y 的数据存储位置是 storage),可行
y[7]; // 返回第 8 个元素,可行
y.length = 2; // 通过 y 修改 x,可行
delete x; // 清除数组,同时修改 y,可行
// 下面的就不可行了;需要在 storage 中创建新的未命名的临时数组, /
// 但 storage 是“静态”分配的:
// y = memoryArray;
// 下面这一行也不可行,因为这会“重置”指针,
// 但并没有可以让它指向的合适的存储位置。
// delete y;
g(x); // 调用 g 函数,同时移交对 x 的引用
h(x); // 调用 h 函数,同时在 memory 中创建一个独立的临时拷贝
}
function g(uint[] storage storageArray) internal {}
function h(uint[] memoryArray) public {}
3,变量具体存储位置举例
3.1 定位固定大小的值
在这个存模型中,究竟是怎么样存储的呢?对于具有固定大小的已知变量,在内存中给予它们保留空间是合理的。Solidity编程语言就是这样做的。
contract StorageTest {
uint256 a;
uint256[2] b; struct Entry {
uint256 id;
uint256 value;
}
Entry c;
}
在上面的代码中:
- a存储在下标0处。(solidity表示内存中存储位置的术语是“下标(slot)”。)
- b存储在下标1和2(数组的每个元素一个)。
- c从插槽3开始并消耗两个插槽,因为该结构体Entry存储两个32字节的值。
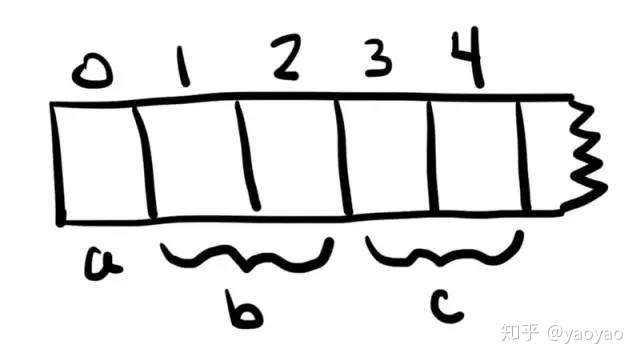
这些下标位置是在编译时确定的,严格基于变量出现在合同代码中的顺序。
3.2 查找动态大小的值
使用保留下标的方法适用于存储固定大小的状态变量,但不适用于动态数组和映射(mapping),因为无法知道需要保留多少个槽。
如果您想将计算机RAM或硬盘驱动器作为比喻,您可能会希望有一个“分配”步骤来查找可用空间,然后执行“释放”步骤,将该空间放回可用存储池中。
但是这是不必要的,因为智能合约存储是一个天文数字级别的规模。存储器中有2^256个位置可供选择,大约是已知可观察宇宙中的原子数。您可以随意选择存储位置,而不会遇到碰撞。您选择的位置相隔太远以至于您可以在每个位置存储尽可能多的数据,而无需进入下一个位置。
当然,随机选择地点不会很有帮助,因为您无法再次查找数据。Solidity改为使用散列函数来统一并可重复计算动态大小值的位置。
3.3 动态大小的数组
动态数组需要一个地方来存储它的大小以及它的元素。
contract StorageTest {
uint256 a; // slot 0
uint256[2] b; // slots 1-2
struct Entry {
uint256 id;
uint256 value;
}
Entry c; // slots 3-4
Entry[] d;
}
在上面的代码中,动态大小的数组d存在下标5的位置,但是存储的唯一数据是数组的大小。数组d中的值从下标的散列值hash(5)开始连续存储。
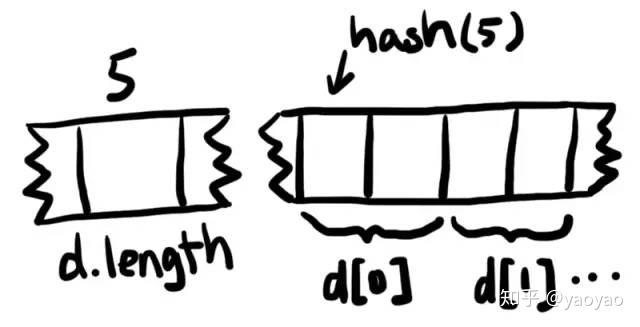
下面的Solidity函数计算动态数组元素的位置:
function arrLocation(uint256 slot, uint256 index, uint256 elementSize)
public
pure
returns (uint256)
{
return uint256(keccak256(slot)) + (index * elementSize);
}
3.4 映射(Mappings)
一个映射mapping需要有效的方法来找到与给定的键相对应的位置。计算键的哈希值是一个好的开始,但必须注意确保不同的mappings产生不同的位置。
contract StorageTest {
uint256 a; // slot 0
uint256[2] b; // slots 1-2
struct Entry {
uint256 id;
uint256 value;
}
Entry c; // slots 3-4
Entry[] d; // slot 5 for length, keccak256(5)+ for data
mapping(uint256 => uint256) e;
mapping(uint256 => uint256) f;
}
在上面的代码中,e的“位置” 是下标6,f的位置是下标7,但实际上没有任何内容存储在这些位置。(不知道多长需要存储,并且独立的值需要位于其他地方。)
要在映射中查找特定值的位置,键和映射存储的下标会一起进行哈希运算。
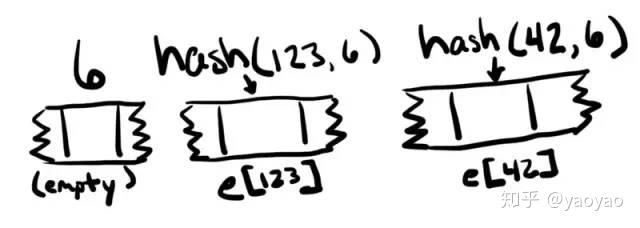
以下Solidity函数计算值的位置:
function mapLocation(uint256 slot, uint256 key) public pure returns (uint256) {
return uint256(keccak256(key, slot));
}
请注意,当keccak256函数有多个参数时,在哈希运算之前先将这些参数连接在一起。由于下标和键都是哈希函数的输入,因此不同mappings之间不会发生冲突。
3.5 复杂类型的组合
动态大小的数组和mappings可以递归地嵌套在一起。当发生这种情况时,通过递归地应用上面定义的计算来找到值的位置。这听起来比它更复杂。
contract StorageTest {
uint256 a; // slot 0
uint256[2] b; // slots 1-2
struct Entry {
uint256 id;
uint256 value;
}
Entry c; // slots 3-4
Entry[] d; // slot 5 for length, keccak256(5)+ for data
mapping(uint256 => uint256) e; // slot 6, data at h(k . 6)
mapping(uint256 => uint256) f; // slot 7, data at h(k . 7)
mapping(uint256 => uint256[]) g; // slot 8
mapping(uint256 => uint256)[] h; // slot 9
}
要找到这些复杂类型中的项目,我们可以使用上面定义的函数。要找到g123:
// first find arr = g[123]
arrLoc = mapLocation(8, 123); // g is at slot 8
// then find arr[0]
itemLoc = arrLocation(arrLoc, 0, 1);
要找到h2:
// first find map = h[2]
mapLoc = arrLocation(9, 2, 1); // h is at slot 9
// then find map[456]
itemLoc = mapLocation(mapLoc, 456);
3.6 总结
- 每个智能合约都以2^256个32字节值的数组形式存储,全部初始化为零。
- 零没有明确存储,因此将值设置为零会回收该存储。
- Solidity中,确定占内存大小的值从第0号下标开始放。
- Solidity利用存储的稀疏性和散列输出的均匀分布来安全地定位动态大小的值。
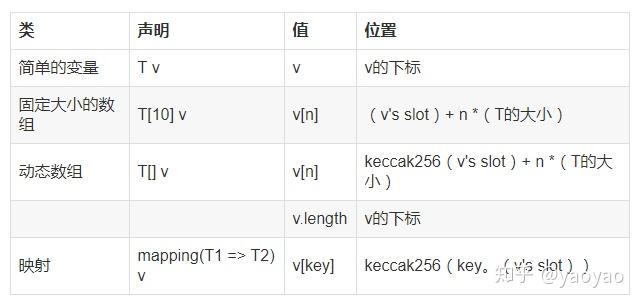
下表显示了如何计算不同类型的存储位置。“下标”是指在编译时遇到状态变量时的下一个可用下标,而点表示二进制串联: